2.10 小结¶
小率把第 2 章的笔记摊开,发现自己已经学会了很多“看清数据”的工具:有的看中心,有的看离散,有的看形状,有的直接画图。
均哥没有让他背公式,而是递来一张检查清单:拿到一份数据时,先判断它是什么,再决定该画什么、算什么、报告什么。
描述统计最怕变成“指标大杂烩”。如果一份报告从头到尾只是均值、标准差、中位数、偏度、峰度排成一张表,读者可能还是不知道数据在讲什么。真正好的描述统计,应该像带读者看一张地图:先指出地图范围,再标出主要城市、道路、山谷和危险地带。
2.10.1 一页看懂本章工具箱¶
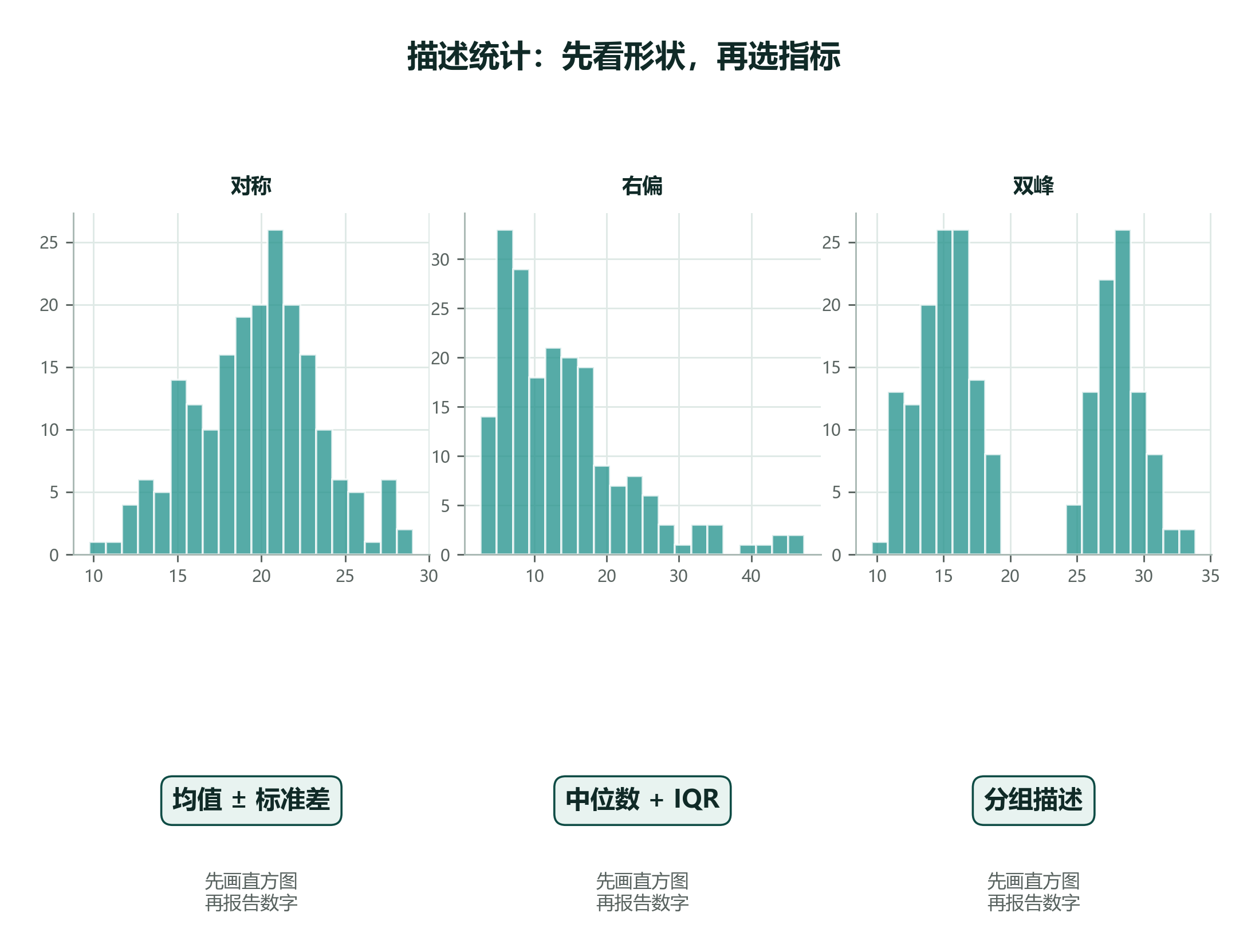
2.10.2 拿到数据先问四个问题¶
小率的复盘题
给你一份新数据,先不要打开计算器。你能先回答下面四个问题吗?
- 观察对象是谁?变量是什么?
- 变量是分类、有序、离散数值,还是连续数值?
- 分布是对称、偏态、双峰,还是有明显异常值?
- 这份数据适合报告均值和标准差,还是中位数和 IQR?
原来描述统计不是“每个指标都算一遍”,而是先判断该算什么。
对。会选择,比会背公式更重要。
这四个问题其实对应本章的四个层次:
| 层次 | 要问什么 | 对应工具 |
|---|---|---|
| 来源 | 数据来自谁,能代表谁 | 总体、样本、抽样偏差 |
| 类型 | 每一列是什么变量 | 分类、数值、有序、连续 |
| 分布 | 数据怎样铺开 | 频数表、直方图、箱线图 |
| 摘要 | 应该报告哪些数字 | 均值、中位数、标准差、IQR、偏度 |
只要这四层说清楚,一份描述统计报告就有了骨架。
2.10.3 核心概念地图¶
| 节 | 关键词 | 一句话记忆 |
|---|---|---|
| 2.1 总体与样本 | \(N\) vs \(n\) | 用样本统计量估计总体参数,是统计推断的起点。 |
| 2.2 变量与数据类型 | 分类 / 数值 | 数据类型决定图形、描述量和模型选择。 |
| 2.3 频数与频率分布 | 频数、直方图 | 把散乱数字分组,先看分布形状。 |
| 2.4 均值 | \(\bar{x}\) | 均值像重心,利用全部数据,但怕极端值。 |
| 2.5 中位数与众数 | Median / Mode | 中位数稳健,众数适合分类变量。 |
| 2.6 方差与标准差 | \(s^2, s\) | 描述数据围绕中心散开多远。 |
| 2.7 极差与 IQR | Range / IQR | IQR 看中间 50%,比极差更稳健。 |
| 2.8 偏度与峰度 | Skewness / Kurtosis | 偏度看歪不歪,峰度看尾巴重不重。 |
| 2.9 数据可视化 | 先画图 | 图形能暴露数字隐藏的结构。 |
2.10.4 描述量怎么搭配报告¶
| 数据形态 | 推荐图形 | 推荐描述量 | 备注 |
|---|---|---|---|
| 对称、无明显异常值 | 直方图 + 箱线图 | 均值 ± 标准差 | 同时报告样本量 \(n\) |
| 右偏长尾或有异常值 | 直方图 + 箱线图 | 中位数 + IQR | 不要只报均值 |
| 分类变量 | 条形图 | 频数 + 比例 + 众数 | 不要计算类别均值 |
| 双峰或多峰 | 分组图 | 分组描述 | 先查是否混合了不同群体 |
| 两个数值变量 | 散点图 | 相关或趋势描述 | 注意离群点和非线性 |
需要注意
“均值 ± 标准差”不是万能模板。偏态、长尾、有异常值或多峰数据,都可能需要更稳健的描述方式。
一个更像人话的报告模板可以这样写:
本次调查共收集 60 位同学的奶茶等待时间。等待时间呈轻微右偏,大多数集中在 10 到 30 分钟之间,少数超过 40 分钟。中位等待时间为 22 分钟,IQR 为 14 到 29 分钟。由于存在长尾,本文主要使用中位数和 IQR 描述典型体验。
这段话没有堆很多指标,却交代了样本量、变量、形状、中心、离散和选择理由。描述统计的目标就是这种清楚表达。
原来报告不是把所有数都端上来,而是把该说的数说清楚。
对。少而准,比多而乱更有用。
2.10.5 Python 复盘:一口气算常用描述量¶
import numpy as np
import pandas as pd
from scipy.stats import skew, kurtosis
rng = np.random.default_rng(210)
data = rng.lognormal(mean=2.2, sigma=0.5, size=100)
summary = {
"样本量": len(data),
"均值": np.mean(data),
"中位数": np.median(data),
"标准差": np.std(data, ddof=1),
"IQR": np.percentile(data, 75) - np.percentile(data, 25),
"偏度": skew(data),
"超额峰度": kurtosis(data),
}
print(pd.Series(summary).round(2))
代码能很快算出一堆数字,但不要让代码替你决定结论。运行完后,至少补三句解释:
- 这组数据是否偏态,是否有长尾或异常值?
- 哪个中心指标更适合报告,为什么?
- 这份数据能代表的范围是什么,不能代表什么?
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/10_summary.py,可以复现本章速查表和复盘示例。
小率的笔记本
- 描述统计的顺序是:先认变量,再画图,再选择合适的描述量。
- 中心、离散和形状要一起看;只报一个平均值通常不够。
- 对称无异常时可以用均值和标准差;偏态长尾时优先用中位数和 IQR。
- 图形不是装饰,而是发现异常值、分组结构和非线性关系的工具。
- 下一章进入概率基础:从“这批数据长什么样”走向“随机现象背后的规律是什么”。
- 一份好的描述统计报告,要说明数据来源、变量含义、分布形状、指标选择和限制。