4.6 正态分布¶
小率把一次模拟考试成绩单拿来。大多数同学集中在平均分附近,特别高和特别低的人都比较少。均哥在便签上画出一条钟形曲线:这就是很多人第一次见到正态分布的样子。

我的分数排在什么位置
如果成绩近似服从正态分布,只知道原始分数还不够;我们还想知道它离平均分有几个标准差。
4.6.1 钟形曲线看中心和波动¶
为什么成绩、身高、测量误差总会提到正态分布?
因为很多变量由许多小因素共同影响,形状常常会接近钟形。
正态分布(Normal Distribution)由两个参数控制:
\[
X\sim N(\mu,\sigma^2)
\]
其中 \(\mu\) 是均值,决定中心位置;\(\sigma\) 是标准差,决定曲线宽窄。
4.6.2 68-95-99.7 法则¶
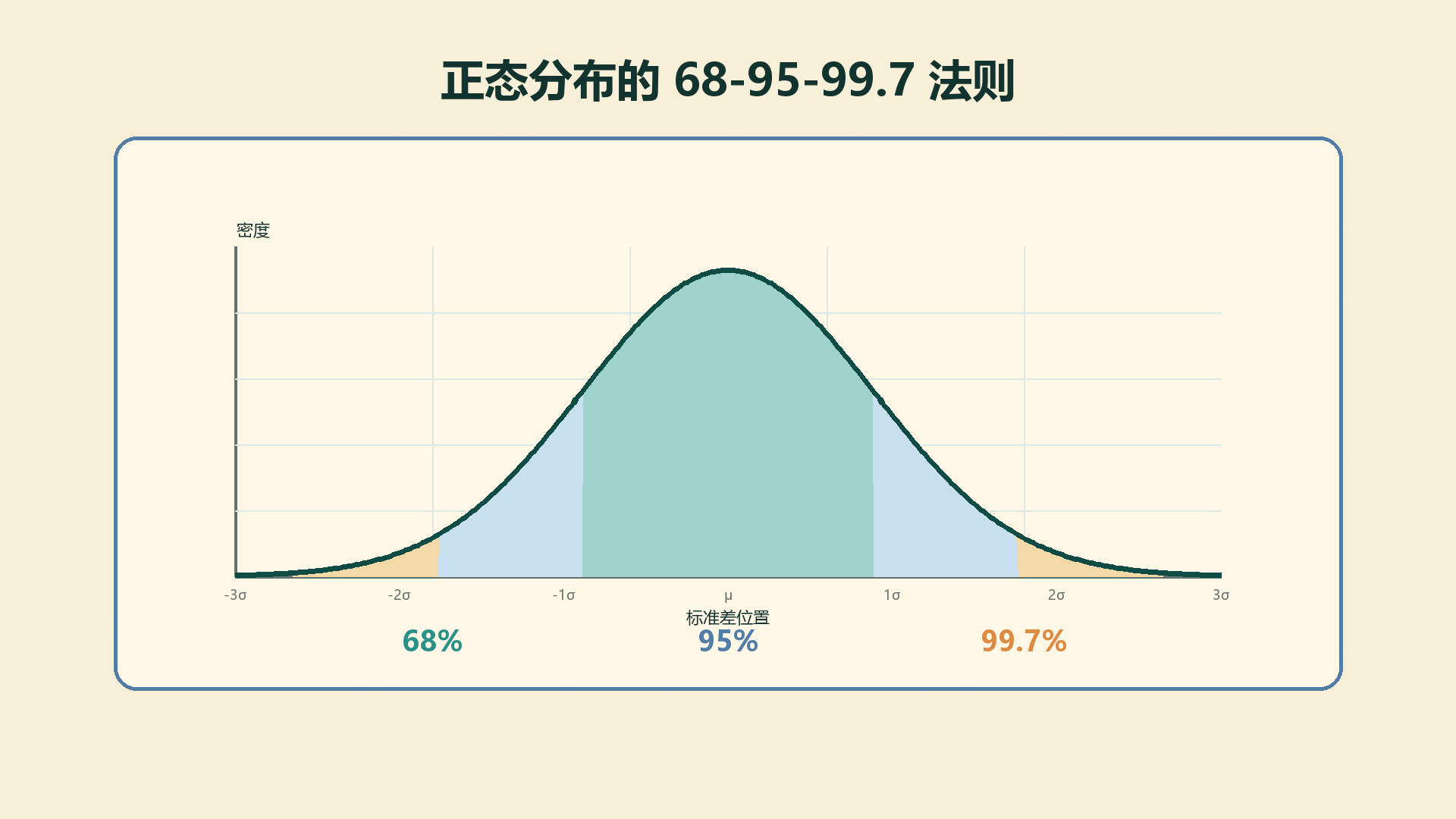
如果平均 70,标准差 10,那 60 到 80 大约覆盖 68%?
对。这是正态分布最值得背下来的直觉。
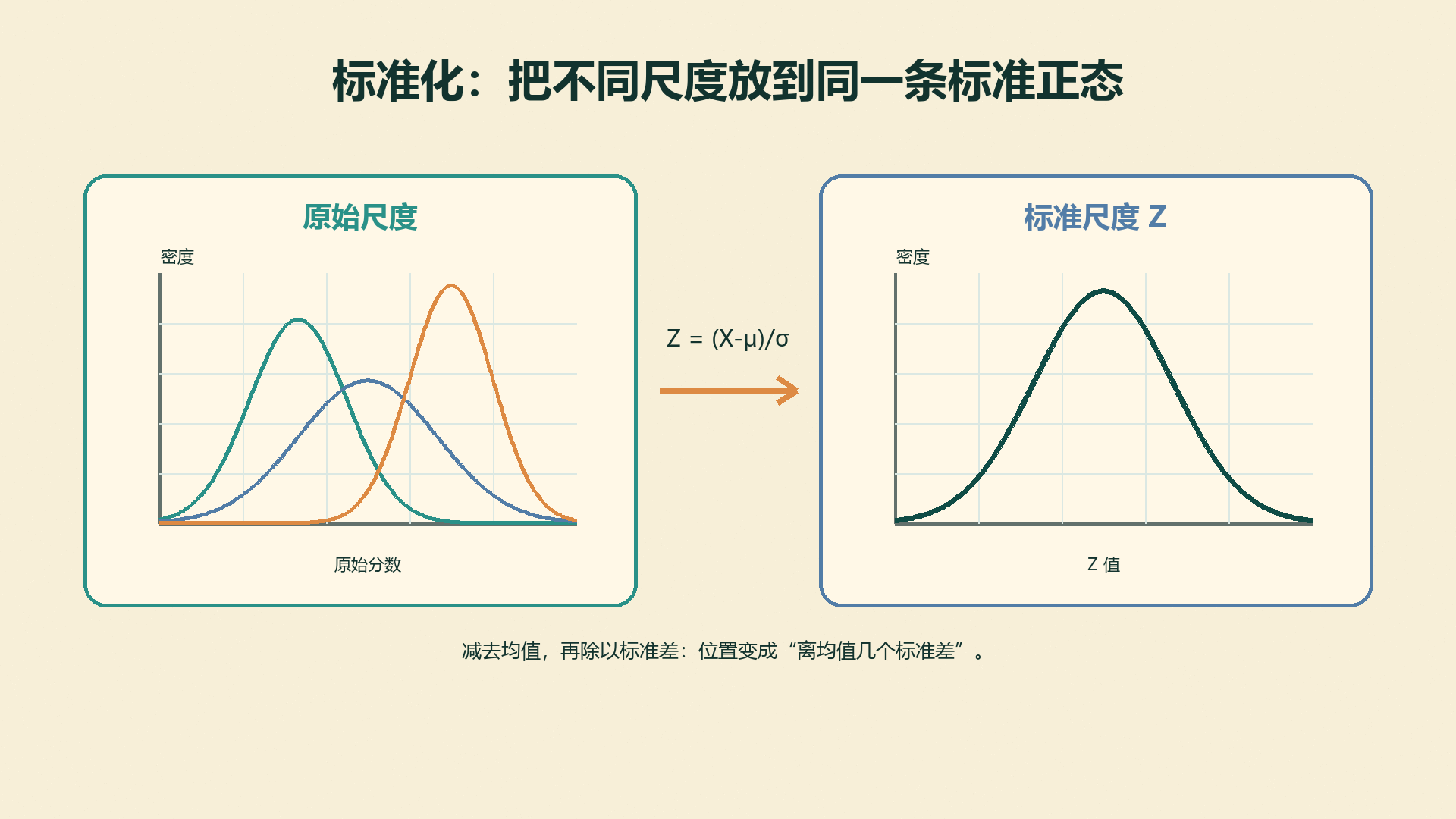
4.6.3 标准化把不同尺度放到同一张表¶
标准化(Standardization)把任意正态变量转成标准正态变量:
\[
Z=\frac{X-\mu}{\sigma}
\]
如果 \(X\sim N(\mu,\sigma^2)\),则:
\[
Z\sim N(0,1)
\]
4.6.4 分数位置要看 z 值¶
假设某次考试平均分 70,标准差 10,小率考了 85 分:
\[
z=\frac{85-70}{10}=1.5
\]
这表示小率比平均分高 1.5 个标准差。
原始分数变成 z 值以后,就能和别的考试比较了。
对。z 值回答的是“相对平均水平高低多少”。
4.6.5 用 Python 查概率和分位数¶
from scipy import stats
mu, sigma = 70, 10
score = 85
z = (score - mu) / sigma
print(f"z 值 = {z:.2f}")
print(f"低于该分数的比例 = {stats.norm.cdf(z):.3f}")
print(f"前 10% 分数线 = {mu + sigma * stats.norm.ppf(0.90):.1f}")
常见问法
- 问“低于某分数的比例”:用
cdf - 问“超过某分数的比例”:用
1 - cdf - 问“前 10% 的分数线”:用
ppf(0.90)
4.6.6 正态不是万能模板¶
正态分布好用,但不是所有数据都该套正态。收入、等待时间、点击次数常常偏斜;考试分数也可能因为满分、难度、分层教学而偏离正态。
所以先看直方图,再决定要不要用正态?
这就很统计学了。模型不是信仰,是工具。
需要注意
正态分布常是近似,而不是现实的命令。使用前最好看图、看背景、看变量是否被上下限截断。
小率的笔记本
- 正态分布由均值 \(\mu\) 和标准差 \(\sigma\) 控制。
- 68-95-99.7 法则是正态分布的核心直觉。
- 标准化公式是 \(Z=(X-\mu)/\sigma\)。
cdf查累计概率,ppf查分位数。- 正态分布很常用,但必须检查是否适合当前数据。