13.2 监督学习与无监督学习¶
社团老师又给小率两项任务。
第一项:根据同学的兴趣、历史活动和空闲时间,预测他最后会不会报名摄影社。第二项:不看报名结果,只根据兴趣和行为,把同学自然分成几类,方便以后设计活动。
同一张表,两个问题都像机器学习。差别藏在一个小小的地方:训练时有没有“参考答案”。
| 同学 | 运动兴趣 | 艺术兴趣 | 活动次数 | 是否报名摄影社 |
|---|---|---|---|---|
| A | 0.8 | 0.2 | 6 | 否 |
| B | 0.1 | 0.9 | 4 | 是 |
| C | 0.4 | 0.7 | 2 | 是 |
| ... | ... | ... | ... | ... |
同一张表,为什么一会儿叫监督学习,一会儿叫无监督学习?
看你训练时用不用“答案列”。有答案学预测,没答案找结构。
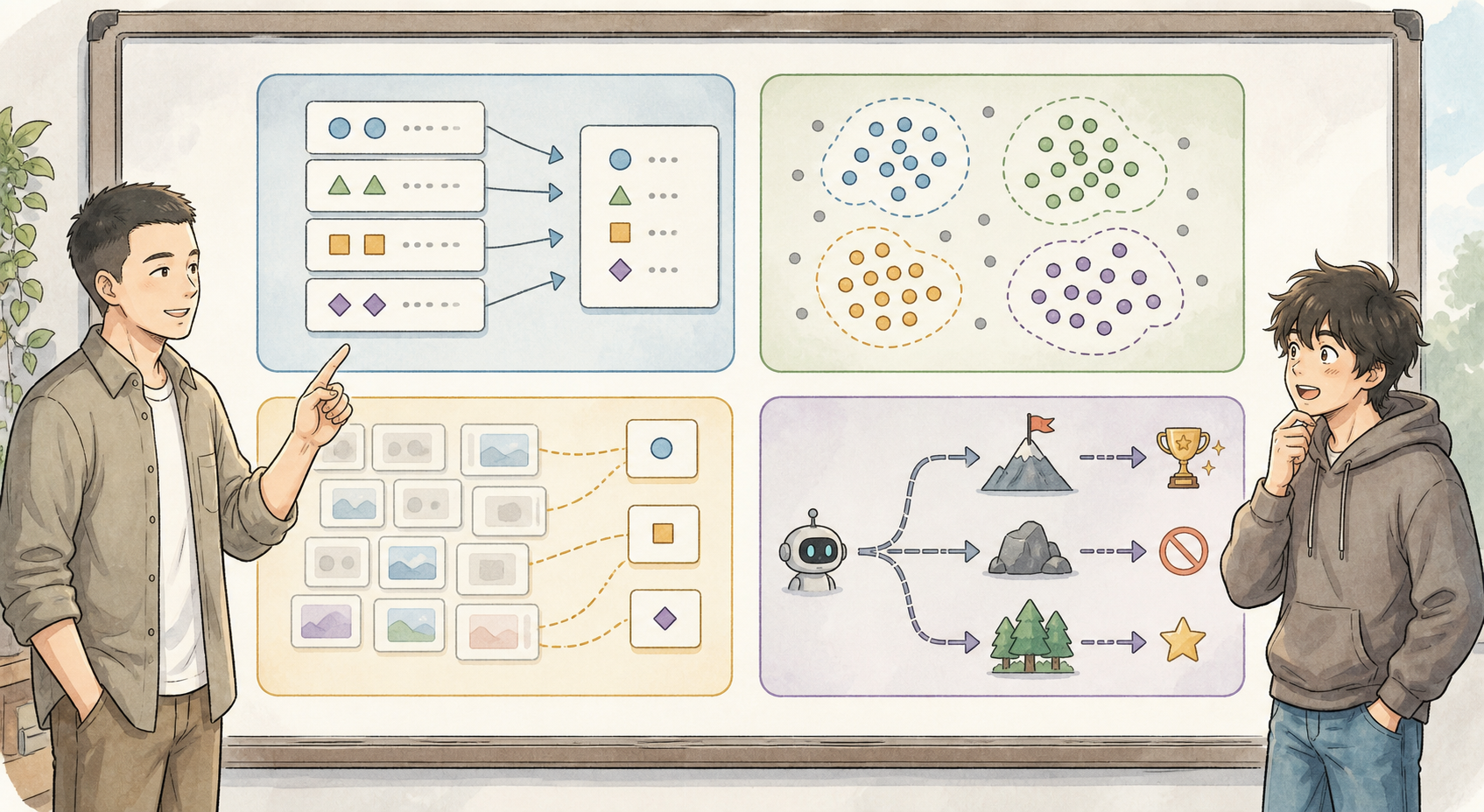
13.2.1 有答案的题叫监督学习¶
监督学习(Supervised Learning) 的训练数据长这样:
\[
\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),\ldots,(\mathbf{x}_n,y_n)\}
\]
每个样本既有输入 \(\mathbf{x}\),也有标签 \(y\)。模型要学:
\[
\hat y=f(\mathbf{x})
\]
如果 \(y\) 是类别,比如“报名 / 不报名”,任务叫 分类(Classification)。如果 \(y\) 是连续数字,比如“预计参加次数”,任务叫 回归(Regression)。
监督学习的关键词
训练时有标签,预测时给新样本标签。分类预测类别,回归预测连续数值。
监督学习里的监督,就是每道练习题后面都附了答案?
对。模型答完之后,可以和答案比一比,再调整规则。
13.2.2 没答案时先找结构¶
无监督学习(Unsupervised Learning) 只有输入:
\[
\{\mathbf{x}_1,\mathbf{x}_2,\ldots,\mathbf{x}_n\}
\]
它没有“是否报名摄影社”这一列,所以不能直接学习 \(\mathbf{x}\to y\)。它常做两类事:
- 聚类(Clustering):把相似同学放到同一组。
- 降维(Dimensionality Reduction):把很多特征压成少数几个坐标,方便观察结构。
在社团数据里,聚类可能发现三类人:运动型、艺术型、社交型。但这些名字不是模型自动懂的,需要人根据每组特征解释。
所以无监督学习给的是线索,不是标准答案。
没错。它像先把地图上的点圈起来,再请人给每个圈命名。
13.2.3 五种学习范式放在一张表里¶
| 范式 | 数据长相 | 典型问题 | 常见方法 |
|---|---|---|---|
| 监督学习 | \((\mathbf{x},y)\) | 分类、回归 | 线性模型、树、神经网络 |
| 无监督学习 | \(\mathbf{x}\) | 聚类、降维 | K-Means、PCA、DBSCAN |
| 半监督学习 | 少量 \((\mathbf{x},y)\) + 大量 \(\mathbf{x}\) | 标签很贵时分类 | 伪标签、标签传播 |
| 自监督学习 | 从数据自身造标签 | 文本、图像表征学习 | 掩码预测、对比学习 |
| 强化学习 | 状态、动作、奖励 | 游戏、控制、策略 | Q-learning、策略梯度 |
先问有没有标签
判断任务类型时,先看训练时是否有目标列 \(y\)。有明确目标列,多半是监督学习;只有特征没有答案,多半是无监督学习。
13.2.4 用 Python 看同一批点的两种问法¶
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
from sklearn.cluster import KMeans
X, y = make_blobs(n_samples=120, centers=2, random_state=2026)
clf = LogisticRegression().fit(X, y)
print("监督学习预测:", clf.predict(X[:5]).tolist())
kmeans = KMeans(n_clusters=2, random_state=2026, n_init="auto").fit(X)
print("无监督聚类编号:", kmeans.labels_[:5].tolist())
监督学习的输出会尽量对齐真实标签;聚类编号只是“第 0 组、第 1 组”,编号本身没有业务含义。
聚类结果不等于真相
聚类算法总能分出一些组,但“这些组是否有意义”要回到场景和数据质量中验证。不要把算法给出的簇名当作自然存在的类别。
小率的笔记本
有标签学预测,没标签找结构。分类和回归属于监督学习;聚类和降维属于无监督学习。半监督、自监督、强化学习都是在“标签从哪里来、反馈怎么来”上继续变化。