13.5 模型评估指标¶
小率做了一个“推荐摄影社”的模型,准确率 95%。他正准备贴到汇报里,均哥让他看原始数据:1000 位同学里,只有 50 位真的报名摄影社。模型把所有人都判成“不报名”,准确率也有 95%。
准确率听起来很高,但它没有找到任何真正会报名的人。
这也能 95%?那准确率岂不是会骗人?
不是准确率骗人,是它回答的问题太粗。指标必须匹配任务代价。
13.5.1 混淆矩阵先把四格摆清楚¶
二分类任务先写成 混淆矩阵(Confusion Matrix):
| 真实会报名 | 真实不报名 | |
|---|---|---|
| 预测会报名 | TP | FP |
| 预测不报名 | FN | TN |
四个格子的含义:
- TP:真正例,会报名的人被找出来。
- FP:假正例,不报名却被误报。
- FN:假负例,会报名却漏掉。
- TN:真负例,不报名也判不报名。
准确率(Accuracy)是:
\[
\text{Accuracy}=\frac{TP+TN}{TP+FP+FN+TN}
\]
在类别极不平衡的数据里,准确率可能被多数类撑得很好看。
13.5.2 Precision 和 Recall 问的是两件事¶
精确率(Precision) 问:预测会报名的人里,有多少真的会报名?
\[
\text{Precision}=\frac{TP}{TP+FP}
\]
召回率(Recall) 问:真实会报名的人里,有多少被找出来?
\[
\text{Recall}=\frac{TP}{TP+FN}
\]
F1 分数(F1 Score) 是二者的调和平均:
\[
F1=\frac{2\cdot\text{Precision}\cdot\text{Recall}}{\text{Precision}+\text{Recall}}
\]
如果摄影社名额少,就怕误报太多;如果想尽量不错过潜在成员,就怕漏报太多。
对。指标背后其实是价值选择。
13.5.3 阈值会改变模型性格¶
很多分类模型先输出概率,再用阈值决定类别。阈值从 0.5 降到 0.2,会让模型更容易报“会报名”:召回率可能上升,误报也会增加。
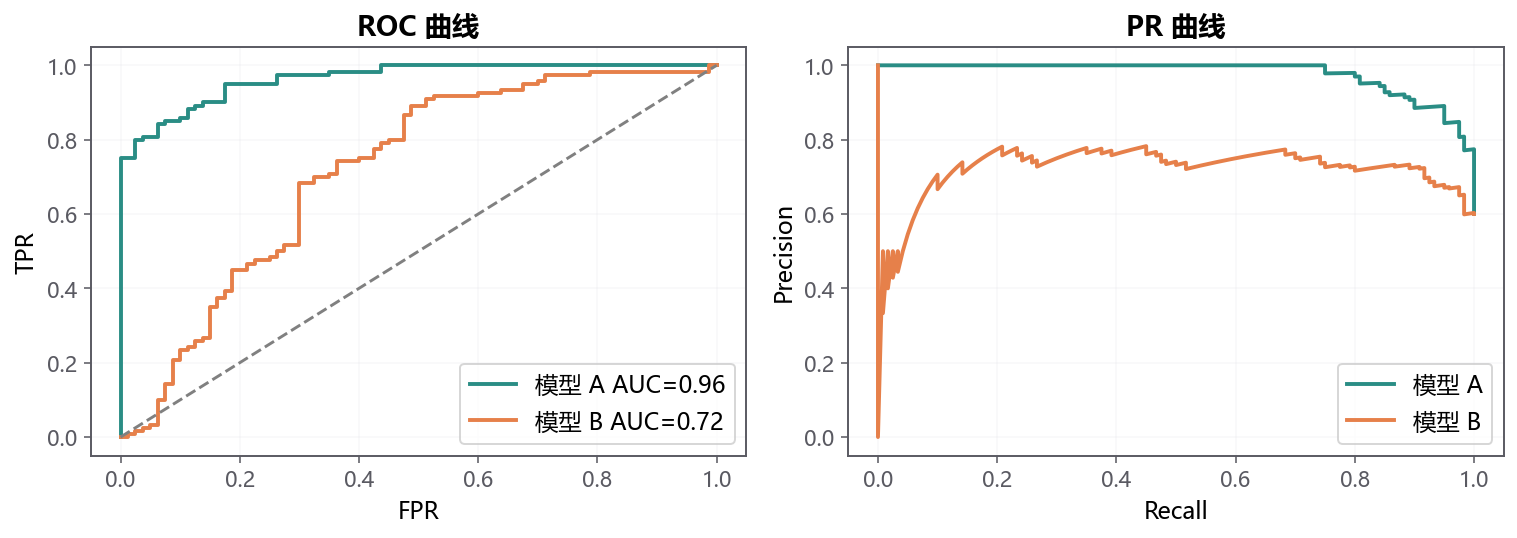
ROC-AUC 看模型把正例排在负例前面的能力;PR-AUC 更关注正例稀少时的 Precision-Recall 表现。类别极不平衡时,PR-AUC 往往更贴近业务感受。
先问错哪种更贵
漏掉潜在成员、误打扰不感兴趣的同学、错推荐冷门活动,它们代价不同。选指标前,先写清楚哪种错误更不能接受。
13.5.4 回归任务看误差大小¶
如果预测的是连续值,比如预计报名人数,常见指标包括:
| 指标 | 公式 | 特点 |
|---|---|---|
| MAE | $\frac{1}{n}\sum | y_i-\hat y_i |
| MSE | \(\frac{1}{n}\sum (y_i-\hat y_i)^2\) | 放大大误差,单位平方 |
| RMSE | \(\sqrt{\frac{1}{n}\sum (y_i-\hat y_i)^2}\) | 与原单位一致,仍惩罚大误差 |
| \(R^2\) | \(1-\frac{\sum(y_i-\hat y_i)^2}{\sum(y_i-\bar y)^2}\) | 相比“永远猜均值”改进多少 |
13.5.5 用 Python 算一组分类指标¶
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score
y_true = [1, 1, 1, 0, 0, 0, 0, 0]
y_score = [0.9, 0.4, 0.2, 0.8, 0.3, 0.2, 0.1, 0.05]
y_pred = [int(p >= 0.5) for p in y_score]
print(confusion_matrix(y_true, y_pred))
print(classification_report(y_true, y_pred, digits=3))
print("ROC-AUC:", round(roc_auc_score(y_true, y_score), 3))
不要让一个指标统治所有任务
排序、筛查、推荐、回归、异常检测的目标不同。一个模型“好不好”,必须先说清楚好在什么任务、什么代价结构下。
小率的笔记本
混淆矩阵是分类指标的底座。Accuracy 看整体命中,Precision 看报正例准不准,Recall 看正例能否找全,F1 平衡二者。回归指标要同时关注平均误差和大误差。