8.2 简单线性回归¶
本节学习目标
- 看懂「用一根直线代表一片散点」是怎么回事,会用最小二乘法 (OLS) 的结果
- 把 \(R^2\) 读成「这根线比一律猜平均强多少」
- 明白同样的广告效应,换一批城市估出来会上下浮动,所以要给一个 区间
- 用
statsmodels在广告数据上跑通拟合、置信区间与预测- (选读)想知道公式是怎么推出来的,看 §8.2.8
8.2.1 多投 1 万广告能换多少销售¶
某连锁奶茶品牌想知道:在不同城市投入的 广告费 究竟带来了多少 销售额 ?市场部从 10 个城市抓了一年的数据,把每个城市的广告投入(万元)和当年销售额(百万元)画成散点图,云团明显向右上方延伸——广告多的城市销售也高。
但老板要的不是『高低』,而是一句具体的话:『再加 1 万广告,平均能带来多少销售?』这个『多少』必须是一根线、一个斜率、一个数字。散点图上能凭眼睛画无数条线,问题是——哪一条最能代表这堆点?
这就是本节的故事:从一片散点云里抠出一根有意义的直线,并诚实地说出『这根线靠不靠谱』。老板还会追问一句更狠的:这根线,到底比『不看广告、一律猜平均销售』强多少?我们一个一个回答。
8.2.2 先用眼睛找那根线¶
把那 10 个城市想成 10 把图钉钉在墙上,你手里有一根橡皮筋直尺。怎么放这把尺,才算『最贴近』这些钉子?
最小二乘法 (OLS) 的回答只有一句:让每个钉子到尺子的竖直距离,平方之后加起来最小。
- 为什么是 竖直 距离?因为我们要回答的是『给定广告投入,销售额偏了多少』,看的是上下方向,不是斜着量。
- 为什么要 平方 ?因为正负偏差不平方就会互相抵消;平方后既都变成正的,又对『偏得特别离谱』的点惩罚更重。
先别急着写公式,用下面这个动画亲手感受一下:每个点是一座城市,橙线是当前这批城市里『最贴近』的那条线。
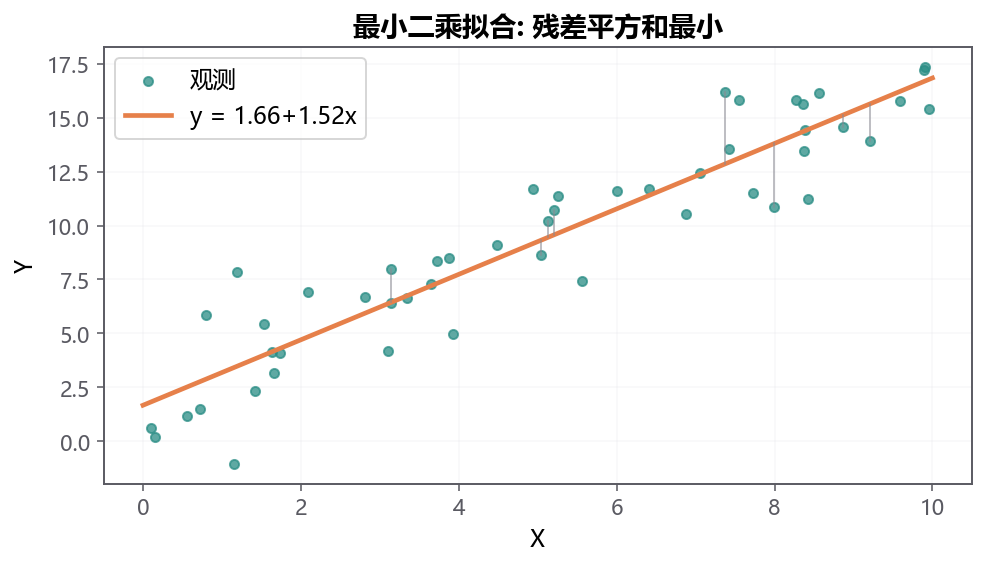
记住三句直觉就够了:(1) OLS 是几何上的『最贴近』;(2) 这条线一定穿过数据的重心 \((\bar{x}, \bar{y})\);(3) 一个离群的极端城市,因为残差被平方,会把整根线撬歪——所以一颗『钉子』也可能让尺子转向。
8.2.3 手把手算出广告的回报¶
直觉有了,怎么把那根线真的算出来?我们假设广告投入 \(x\) 和销售额 \(y\) 背后有一条 真实直线,但每座城市还会被随机因素(节假日、对手、天气)扰一下:
- \(\beta_1\) 是 斜率:广告每多投 1 万,销售平均多多少——老板真正想要的那个数;
- \(\beta_0\) 是 截距:完全不打广告时的销售底盘;
- \(\varepsilon\) 是没法解释的随机扰动。
OLS 解出的『最贴近直线』有一个现成的公式,先 拿来用(它是怎么推出来的,放在 §8.2.8 选读):
市场部那 10 个城市,先算几个汇总量:广告均值 \(\bar{x}=5\)、销售均值 \(\bar{y}=15\),再算出 \(\sum (x_i-\bar{x})^2 = 80\)、\(\sum (x_i-\bar{x})(y_i-\bar{y}) = 128\)。代进去:
顺带一个漂亮的小发现:这个斜率正好等于 上一节的相关系数 \(r\) 换算了单位,即 \(\hat{\beta}_1 = r \cdot s_y / s_x\)。换句话说,回归就是给『相关』装上了单位——相关说『同涨同跌有多齐』,回归说『多 1 万换几百万』。
你知道吗
『最小二乘法』之父是高斯(Gauss)。1801 年,他用这套方法根据天文学家仅有的少量观测,预测了小行星 Ceres 重新出现的位置——结果完全准确,震惊了整个欧洲天文学界。同一时期勒让德(Legendre)也独立发表了同样的方法,两人为优先权争论已久;但今天公认高斯不仅更早,还配套证明了它在『正态误差』下的统计最优性。
8.2.4 这根线画得好不好:R²¶
线画好了,怎么说它『画得好』?StatQuest 有个特别好用的问法:拿你的线,去跟一个 最笨的基准 比。
- 最笨的基准(只猜均值):完全不看广告,对每座城市都预测销售 \(=\bar{y}\)。这时数据围着均值上下散开的总量,记作 \(\text{SS(mean)}\)。
- 你的拟合线(用上广告):预测 \(\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\)。这时数据围着拟合线还剩下的散开量,记作 \(\text{SS(fit)}\)。
用了广告之后『被消掉』的那部分散开量,占原来的比例,就是 决定系数 \(R^2\):
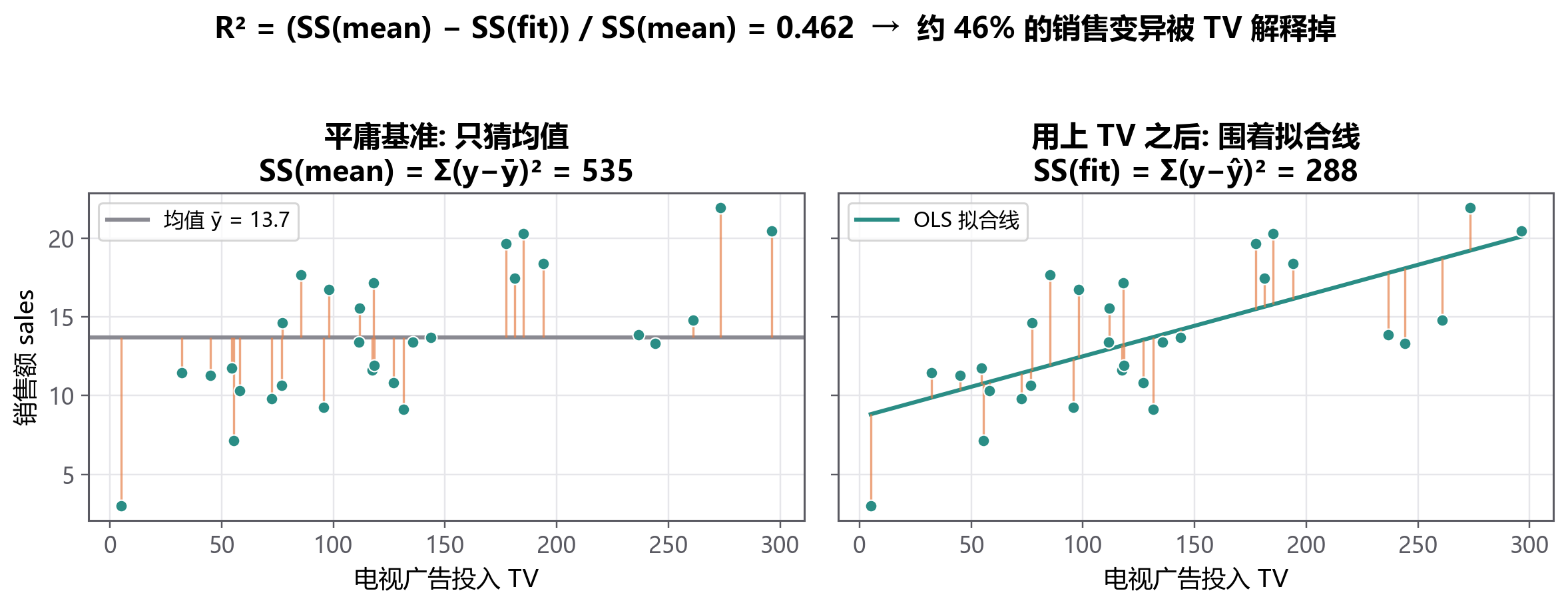
写成课本里的记号也一样:\(\text{SS(mean)}\) 是总变异 SST,\(\text{SS(fit)}\) 是残差 SSE,于是 \(R^2 = 1 - \text{SSE}/\text{SST}\),取值在 \(0\) 到 \(1\) 之间,越大越好。简单线性回归里还有个巧合:\(R^2 = r^2\),正好是相关系数的平方。
10 个城市的例子算出来 \(R^2 \approx 0.91\),也就是说 广告一个因素,就解释了九成的销售差异。如果还想知道『预测一座新城市平均会差多少』,看 残差标准误 \(s\)(相当于这根线的『典型误差棒』),它就是把剩下的散开量摊到每个点上再开方。
8.2.5 斜率靠不靠谱:换一批城市试试¶
上面那个 \(1.6\),是从 这 10 座城市 算出来的。要是市场部当初抽的是另外 10 座城市呢?
下面的动画就在干这件事:假设广告的真实效应是 \(1.6\),反复『再抽一组城市』,每组各算一次广告效应的估计,把它们堆成柱子。
所以一个估计光报 \(1.6\) 是不够的,还得告诉别人它『能飘多远』。统计学用 标准误 \(\text{SE}(\hat{\beta}_1)\) 量这个飘动幅度,再据此给一个 置信区间(用法先记住,推导见 §8.2.8):
回到 10 城的例子,算出 \(\text{SE}(\hat{\beta}_1) \approx 0.18\),于是:
- \(t = 1.6 / 0.18 \approx 9.0\),远大于临界值——几乎不可能是『广告其实没用』的巧合;
- 95% 置信区间约 \([1.19,\ 2.01]\)。
老板要的答案于是变成一句更诚实的话:每万元广告大约带来 1.2 ~ 2.0 百万销售,最佳猜测 1.6。
8.2.6 预测一个新城市:两种区间¶
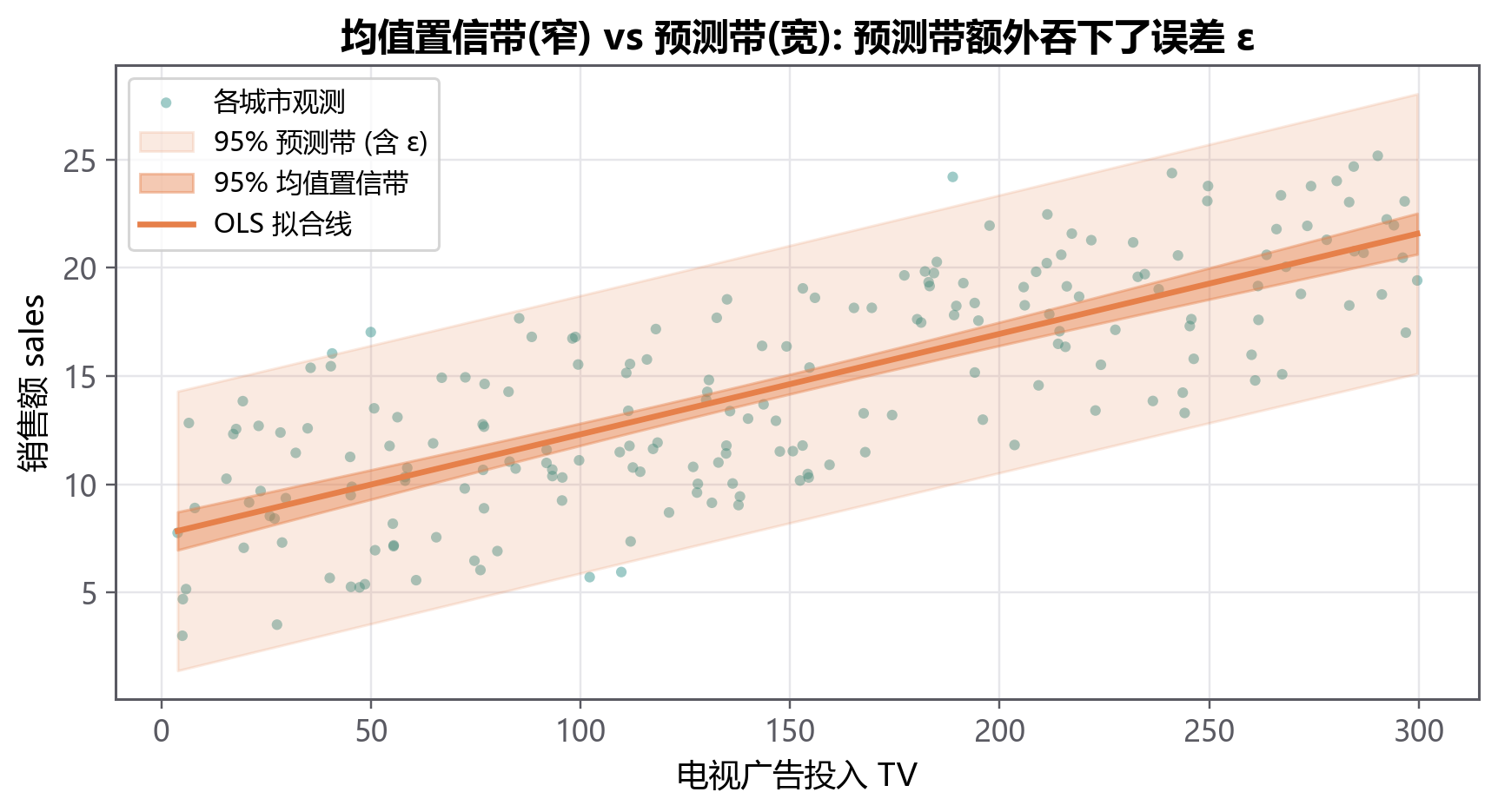
回归这根线有两种用法:解释(盯着斜率 \(1.6\) 说『广告的边际效应』,但要不要读成因果,先回看 §8.1)和 预测(给一座新城市的广告投入 \(x_0\),估它的销售)。
做预测时要分清你问的是哪一种,因为区间宽窄差很多:
- 问『一类城市的平均销售』(均值置信区间):只有那根线本身的不确定,区间 窄。
- 问『某一座具体城市的销售』(预测区间):除了线的不确定,还要再加上这座城市自己的随机扰动 \(\varepsilon\),区间 宽 得多。
公式里那个孤零零的 +1,就是『还没发生的随机扰动』——它只出现在预测区间里。还有一点:\(x_0\) 离样本中心越远,根号里的 \((x_0-\bar{x})^2\) 越大,两种区间都越宽。
应用场景
营销 ROI 估计、电商定价(销量 vs 价格弹性)、临床剂量-效应曲线、传感器线性校准——只要相信 \(X\) 与 \(Y\) 在你关心的范围里近似一条直线,简单线性回归就是最透明、最易复盘的工具。
8.2.7 用 Python 把广告数据跑到底¶
我们造一份带固定随机种子、可复现的 拟真广告数据(200 座城市,电视 / 广播 / 报纸投入 → 销售额,系数呼应 ISLP 第 3 章),先只用电视广告 TV 做简单回归。完整脚本见 docs/assets/scripts/ch08_regression/02_simple_linear_regression.py。
import numpy as np, pandas as pd
import statsmodels.formula.api as smf
rng = np.random.default_rng(8) # 固定 seed -> 结果可复现
n = 200
TV = rng.uniform(0, 300, n)
sales = 2.9 + 0.046 * TV + rng.normal(0, 1.7, n)
df = pd.DataFrame({"TV": TV, "sales": sales})
model = smf.ols("sales ~ TV", data=df).fit()
print(model.summary()) # ① 一张完整报告
print(model.conf_int()) # ② 系数的置信区间
new = pd.DataFrame({"TV": [50, 150, 250]})
print(model.get_prediction(new).summary_frame()) # ③ 平均区间 vs 预测区间
① 报告(节选) ——表里每个数字,都能在前几节找到对应的那句话:
coef std err t P>|t| [0.025 0.975]
Intercept 7.6631 0.455 16.835 0.000 6.765 8.561
TV 0.0464 0.003 17.096 0.000 0.041 0.052
R-squared: 0.596 F-statistic: 292.3 Prob (F): 7.58e-41 n = 200
| 报告里这一栏 | 就是前面说的 | 这里读到什么 |
|---|---|---|
coef (TV) |
斜率 \(\hat{\beta}_1\)(§8.2.3) | 每多 1 单位电视广告,销售平均 +0.046 |
std err |
标准误 \(\text{SE}\)(§8.2.5) | 这个估计能飘 \(\pm 0.003\) |
t / P>\|t\| |
\(t\) 检验(§8.2.5) | \(t=17\)、\(p\approx 0\),广告 确实有用 |
R-squared |
\(R^2\)(§8.2.4) | 单靠电视广告解释了 约 60% 的销售差异 |
② 置信区间 model.conf_int() 给出 \(\hat{\beta}_{TV}\) 的 95% 区间 \([0.0411,\ 0.0518]\)——和报告最后两栏一致。
③ 平均区间 vs 预测区间 get_prediction(...).summary_frame():
TV mean mean_ci_lower mean_ci_upper obs_ci_lower obs_ci_upper
50 9.984 9.304 10.664 3.557 16.411
150 14.626 14.173 15.078 8.219 21.032
250 19.267 18.545 19.989 12.836 25.699
看 \(TV=150\):『一类城市的平均销售』区间 \([14.17, 15.08]\) 又窄又稳;『某一座城市的销售』区间 \([8.22, 21.03]\) 宽得多。这正是 §8.2.6 那个 +1 的代价,画出来就是上面 图 8.2.3 的内窄外宽两条带。
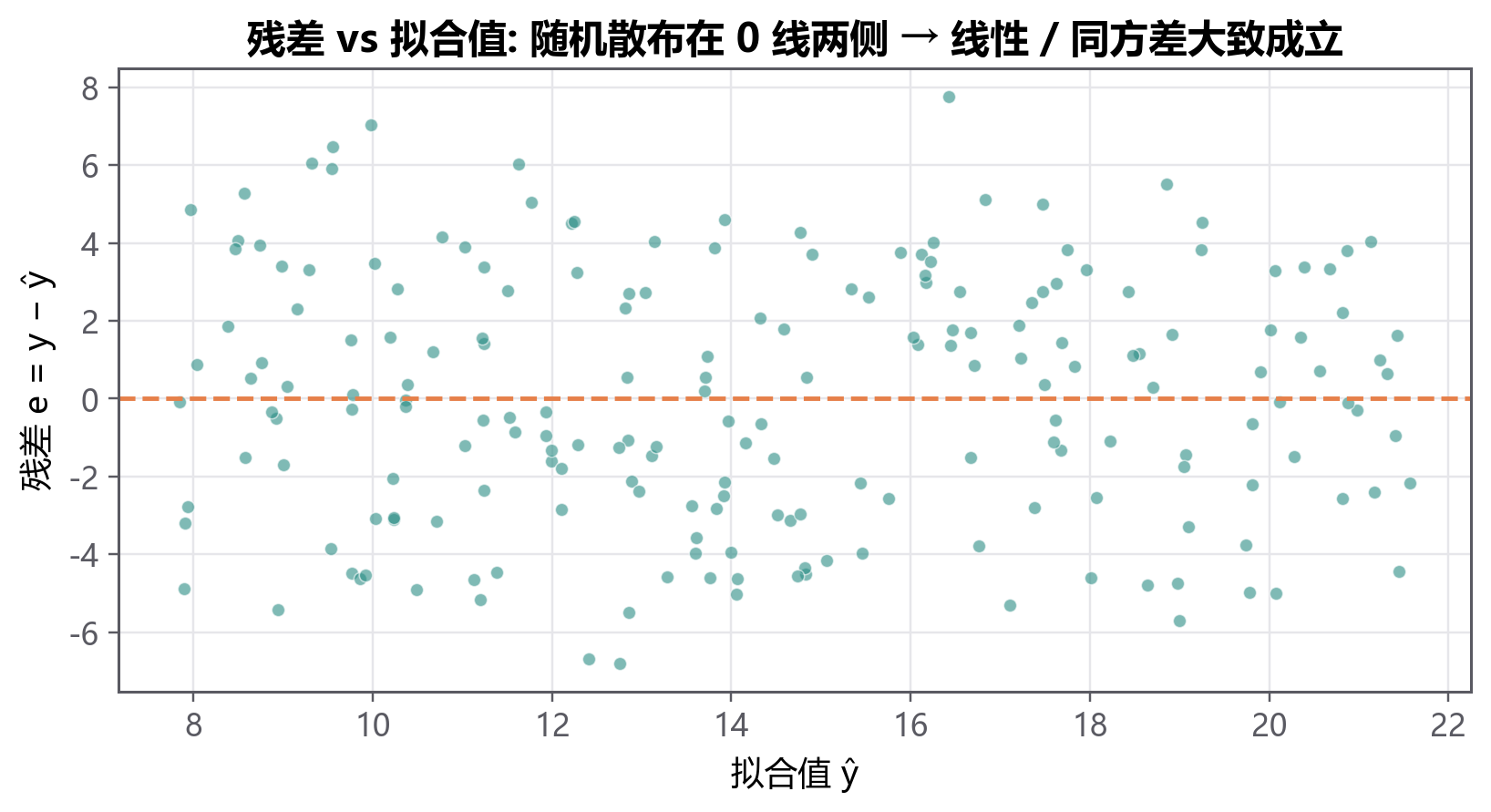
最后给模型做个体检:把残差对拟合值画出来,看有没有违反假设(喇叭口、弯曲趋势都是警报)。
8.2.8 选读 · 公式从哪来:正规方程到抽样分布¶
前面我们一直『拿来就用』。这一节把那几个公式补上推导,给想深究的读者;只想会用的,可以直接跳到小结。
一、闭式解:两条正规方程¶
要让残差平方和 \(\text{RSS} = \sum (y_i - \beta_0 - \beta_1 x_i)^2\) 最小,对 \(\beta_0, \beta_1\) 分别求偏导并置 0,得到两条 正规方程 (normal equations) :
第一条 \(\sum e_i = 0\) 正是『拟合线必过重心 \((\bar{x}, \bar{y})\)』的代数原因;两条联立就解出 §8.2.3 那个闭式公式。
二、\(\hat{\beta}_1\) 的无偏性、方差与抽样分布¶
把 \(X\) 看作固定,唯一的随机性来自误差。记 \(S_{xx} = \sum (x_i - \bar{x})^2\),闭式解可写成 \(Y_i\) 的线性组合:
无偏(估计的期望等于真值):
方差与标准误(各 \(Y_i\) 独立、方差都是 \(\sigma^2\),且 \(\sum w_i^2 = 1/S_{xx}\)):
这就解释了动画 8.2.2 的现象:城市越多 \(S_{xx}\) 越大,柱子越窄;噪声 \(\sigma\) 越大,柱子越宽。误差正态时,\(\hat{\beta}_1\) 也正态,用估计的 \(\hat{\sigma}\) 代替 \(\sigma\) 后变成 \(t\) 分布:
为什么是 \(n-2\):两条正规方程各锁住一个自由度,残差只在 \(n-2\) 维里自由活动,用 \(n-2\) 作分母才能让 \(\hat{\sigma}^2 = \text{SSE}/(n-2)\) 无偏。这正是 §8.2.4 残差标准误里那个 \(n-2\) 的来历。
三、Gauss-Markov 与 OLS = MLE¶
Gauss-Markov 定理:只要满足 线性、误差不相关、同方差 这三条(注意:不含正态性),OLS 就是 最佳线性无偏估计 (BLUE) ——所有无偏的线性估计里方差最小。
正态性是 额外 的一条,它的用处有两个:让 §8.2.5 的 \(t\)、\(F\) 检验是 精确 的;以及——当误差正态时,最大化似然恰好等于最小化残差平方和。写出高斯对数似然:
对 \(\beta\) 求极大只跟最后那个求和项有关,而它正是 RSS,于是 \(\hat{\beta}^{\text{MLE}} = \hat{\beta}^{\text{OLS}}\)。
8.2.9 本节小结¶
- OLS 的规则只有一句:竖直残差平方和最小,由此得到唯一的最优直线,斜率 \(\hat{\beta}_1 = r \cdot s_y/s_x\)。
- \(R^2\) = 围着均值的散开被消掉了几成(\(\text{SS(mean)}\) 与 \(\text{SS(fit)}\) 之差占比),等价于 \(1-\text{SSE}/\text{SST}\)。
- 同一个斜率,换一批样本会上下飘;飘动幅度就是标准误,据此给 置信区间,点估计和区间要一起报。
- 预测『一类城市的平均』用窄的置信区间,预测『某一座城市』用宽的预测区间——后者多吞一个随机扰动 \(\varepsilon\),外推还要付『区间变宽』的代价。
- 想深究公式来历看 §8.2.8:正规方程、无偏性、\(\text{Var}=\sigma^2/S_{xx}\)、\(t_{n-2}\)、Gauss-Markov 与 OLS=MLE。
- 下节 §8.3 把 1 个 \(X\) 推广到 \(p\) 个 \(X\),进入多元线性回归。