2.6 方差与标准差¶
周五放学,小率和均哥在公交站等车。
站牌上有两条线路。手机记录显示,两条线路过去 10 次的平均等待时间都差不多,都是大约 10 分钟。小率本来以为它们一样靠谱,可实际等起来,感觉完全不同:A 线几乎每次都在 8 到 12 分钟之间;B 线有时 1 分钟就来,有时要等 40 分钟。
小率看着两组记录,有点不解。
均哥把两组等待时间写在纸上:

均值告诉我们中心在哪里,但没有告诉我们数据散得有多开。描述统计不能只问“平均多少”,还要问:
大多数值离中心有多远?
这就是方差(Variance)和标准差(Standard Deviation)登场的原因。
在生活里,离散程度常常比平均值更影响体验。两条公交线路平均等待时间都差不多,一条每次都差不多 10 分钟,另一条有时 1 分钟、有时 40 分钟,你对它们的信任感完全不同。统计学把这种“稳不稳”的感觉,变成可以计算、可以比较的指标。
2.6.1 同样的平均值,可以有完全不同的波动¶
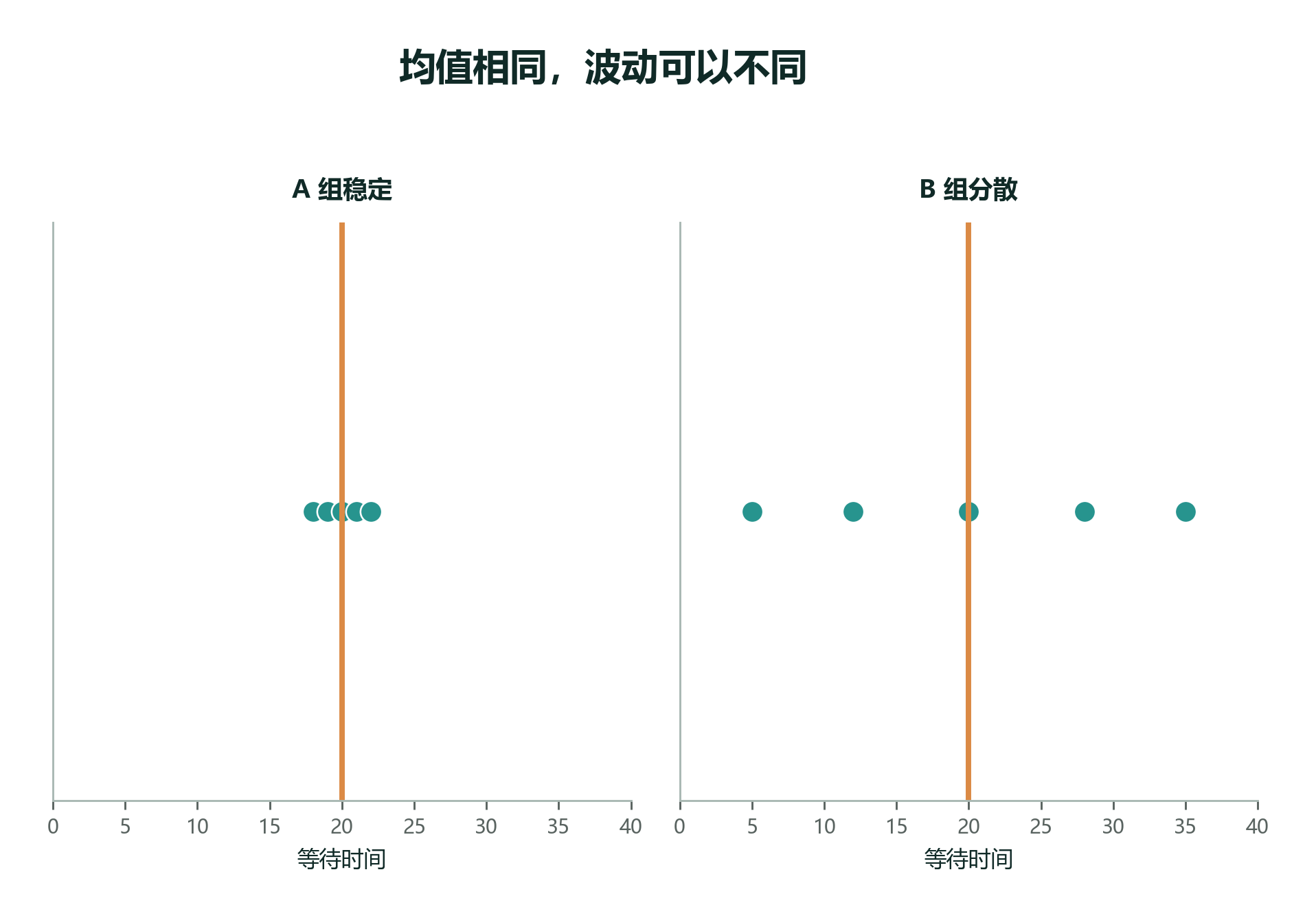
先看一个更短的例子:
两组均值都是 20。
但 A 组很整齐,B 组忽高忽低。只报“平均 20”,会把这种差异藏起来。
2.6.2 从“离平均有多远”开始¶
要描述波动,最自然的想法是:看每个值离均值有多远。
以 A 组为例:
| 数值 | 离均值 20 的距离 |
|---|---|
| 18 | -2 |
| 19 | -1 |
| 20 | 0 |
| 21 | 1 |
| 22 | 2 |
这些差值叫偏差:
但如果直接相加:
正负抵消了。数据明明有波动,相加却变成 0。
所以我们需要一个办法,让“离得远”不会被正负方向抵消。常见办法是平方。
小率在纸上把每个偏差画成小箭头:比均值小的箭头向左,比均值大的箭头向右。箭头方向说明“偏高还是偏低”,箭头长度说明“离得有多远”。如果只把箭头相加,左箭头和右箭头会抵消;如果关心波动,我们真正想保留的是长度。
2.6.3 方差:平均的平方偏差¶
把每个偏差平方,再求平均,就得到方差的核心思想。
对样本数据,样本方差(Sample Variance)写作:
先别急着被公式吓到。它只是在说:
- 每个数都减去均值。
- 把差值平方。
- 把这些平方后的差值加起来。
- 再除以一个合适的数量。
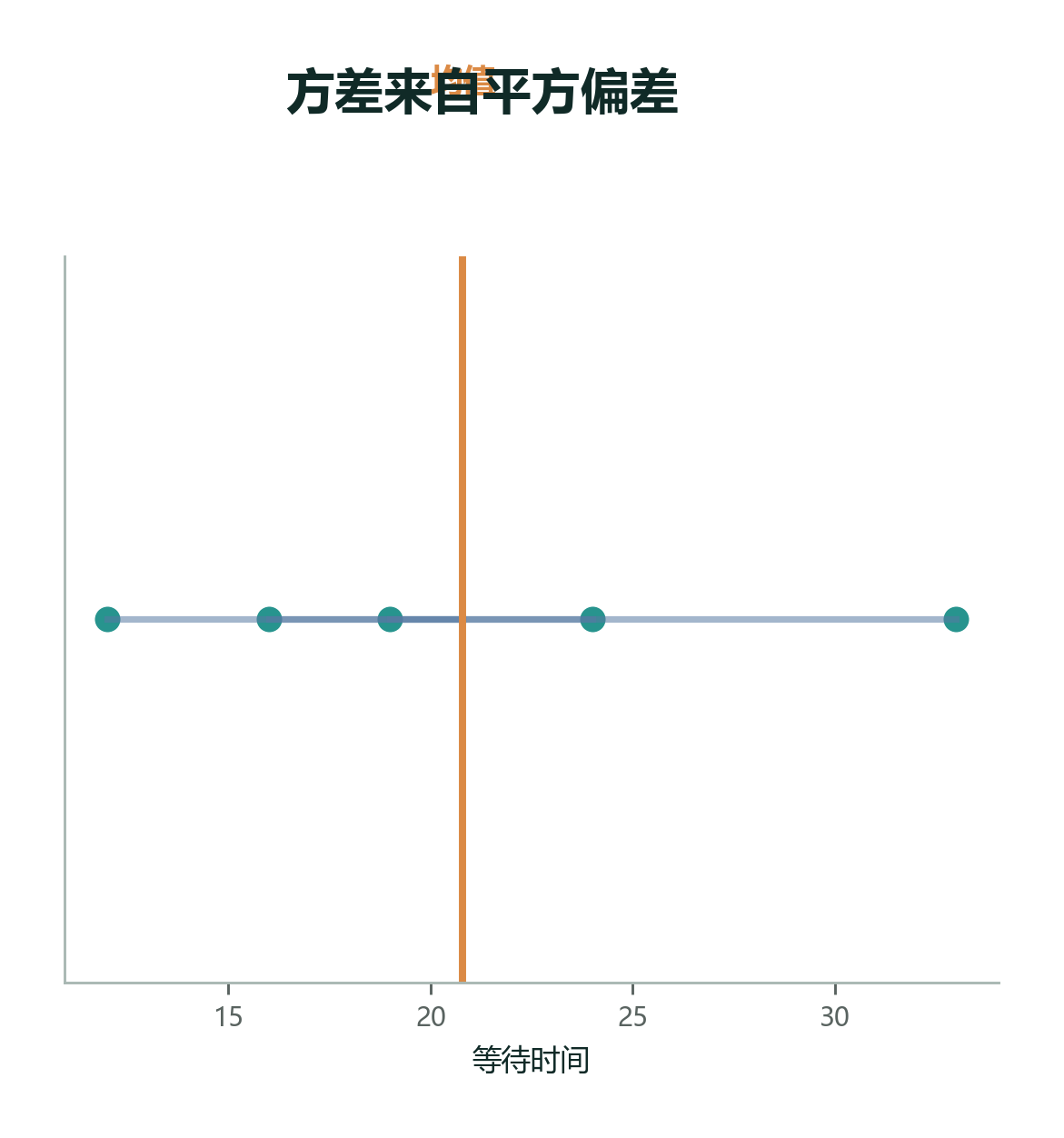
用前面的 A 组手算一遍:
| 数值 | 偏差 | 偏差平方 |
|---|---|---|
| 18 | -2 | 4 |
| 19 | -1 | 1 |
| 20 | 0 | 0 |
| 21 | 1 | 1 |
| 22 | 2 | 4 |
平方偏差加起来是 \(4+1+0+1+4=10\)。如果把这 5 个数看成一个样本,用 \(n-1=4\) 做分母:
这一步的重点不是背公式,而是看见方差的逻辑:每个点都要先和均值比较,离得越远,平方后贡献越大。
2.6.4 标准差:把单位变回人能读懂的样子¶
方差有一个尴尬点:单位会被平方。
如果等待时间的单位是“分钟”,方差的单位就变成“分钟平方”。这听起来很别扭。
所以我们对方差开平方,得到 标准差(Standard Deviation):
标准差和原数据单位一致。等待时间的标准差仍然是“分钟”,月薪的标准差仍然是“元”,考试成绩的标准差仍然是“分”。
一句话记忆
方差适合数学推导,标准差适合和人沟通。报告一组数据时,通常说“均值 + 标准差”比只说方差更直观。
2.6.5 标准差大,生活感受会怎样¶
回到公交等待时间。
如果 A 线平均等待 10 分钟,标准差很小,你大概能放心安排时间:多数时候不会差太多。
如果 B 线平均等待也 10 分钟,但标准差很大,你的体验会更像抽签:有时惊喜,有时崩溃。
这就是标准差的生活含义:
| 场景 | 标准差小 | 标准差大 |
|---|---|---|
| 公交等待 | 基本准时 | 有时很快,有时很久 |
| 考试成绩 | 大多数人接近 | 有人很高,有人很低 |
| 产品尺寸 | 质量稳定 | 批次差异明显 |
| 每日步数 | 生活节奏稳定 | 有些天很多,有些天很少 |
标准差不是“好”或“坏”。它只是告诉我们:这组数据有多稳定。
同样是公交等待时间,标准差的意义也要放回线路背景里解释。A 线标准差小,说明发车节奏稳定;B 线标准差大,可能说明班次间隔不均、拥堵影响明显,或者这条线在高峰期和非高峰期差异很大。
所以解释标准差时一定要回到故事本身。统计量只给出形状,业务背景决定它意味着什么。
一句话读标准差
先说单位,再说含义。比如“B 线等待时间标准差约 11 分钟”比“标准差等于 11”更清楚;再补一句“说明这条线路的等待体验很不稳定”。
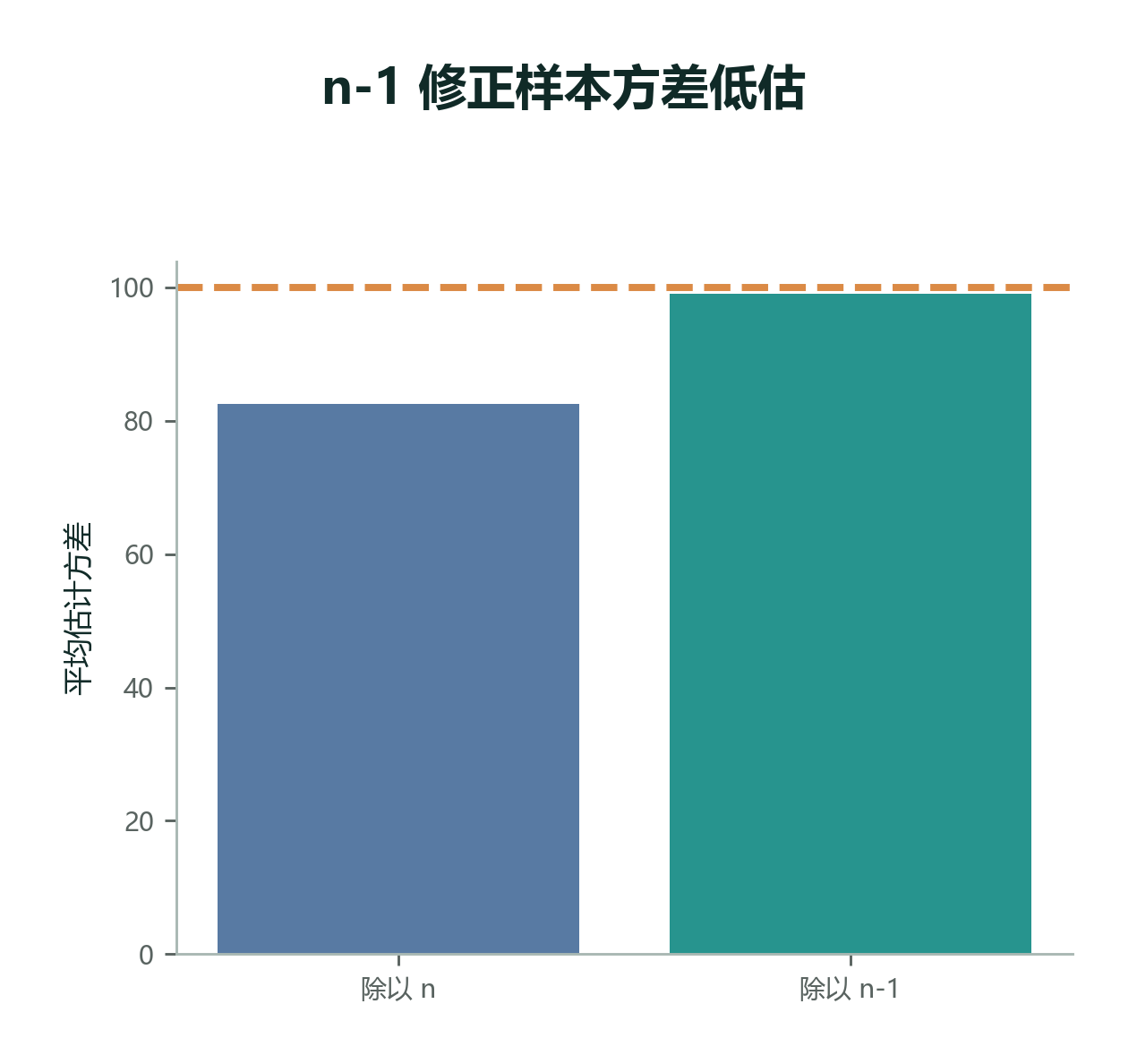
2.6.6 为什么样本方差常常除以 n-1¶
样本方差公式里常见的是 \(n-1\),不是 \(n\)。
直觉上,这是因为样本均值 \(\bar{x}\) 已经用这组数据估计出来了。数据的偏差不再完全自由:前面几个偏差确定后,最后一个偏差会被“总和为 0”这个条件限制住。
先记住结论
如果只是描述手上这一组完整数据,有些软件会用分母 \(n\)。如果用样本去估计更大总体的方差,统计学通常使用分母 \(n-1\)。更严格的解释会在参数估计章节展开。
初学阶段可以这样记:如果这组数据就是你要描述的全部,比如一个小组 5 个人的全部成绩,用 \(n\) 也说得通;如果这组数据只是从更大人群中抽出来的样本,希望用它推断总体波动,通常用 \(n-1\)。在 Python 里,ddof=1 就是在告诉软件“分母用 \(n-1\)”。
ddof=1,就想到样本方差?
2.6.7 用 Python 计算方差和标准差¶
import numpy as np
a = np.array([18, 19, 20, 21, 22])
b = np.array([5, 12, 20, 28, 35])
for name, data in [("A 组", a), ("B 组", b)]:
print(name)
print(f"均值 = {data.mean():.1f}")
print(f"样本方差 = {data.var(ddof=1):.1f}")
print(f"样本标准差 = {data.std(ddof=1):.1f}")
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/06_variance_and_std.py,可以复现方差、标准差和 \(n-1\) 的比较。
小率的笔记本
- 均值描述中心,标准差描述数据围绕中心散开多远。
- 方差是平均的平方偏差,样本方差常用分母 \(n-1\)。
- 标准差是方差开平方,单位和原数据一致,更适合解释。
- 两组数据均值一样,标准差可能很不一样;只看均值会漏掉“稳定性”。
- 标准差要放回场景解释:在公交等待里,它代表线路稳定性,而不只是一个抽象数字。