2.3 频数与频率分布¶
周末奶茶店门口排了很长的队。小率帮社团做了一次小调查,记录 60 位同学从下单到拿到奶茶的等待时间。数字贴在纸上后,他只觉得密密麻麻,像一串没有标点的句子。
均哥说,描述统计的第一项本领,就是给数字加上“段落”:先数一数每个范围里有多少个,再看整体形状。

2.3.1 先把散乱数字分组¶
奶茶等待时间怎么分布
60 位同学的奶茶等待时间已经记好。不要急着算平均值,先回答:多数人等了多久?有没有特别久的等待?
小率的原始记录长这样:
| 同学 | 等待时间(分钟) | 同学 | 等待时间(分钟) |
|---|---|---|---|
| A | 12 | B | 18 |
| C | 24 | D | 31 |
| E | 17 | F | 43 |
| ... | ... | ... | ... |
这些数每一个都是真实记录,但直接摊开时很难看出整体。就像一篇文章没有逗号、句号和段落,字都认识,却读不出意思。频数表做的事,就是给数字分段。
频数(Frequency) 是某个类别或区间中出现的次数。
频率(Relative Frequency) 是频数除以总样本量:
| 等待时间区间 | 频数 | 频率 |
|---|---|---|
| 0-10 | 6 | 0.10 |
| 10-20 | 24 | 0.40 |
| 20-30 | 21 | 0.35 |
| 30-40 | 7 | 0.12 |
| 40-50 | 2 | 0.03 |
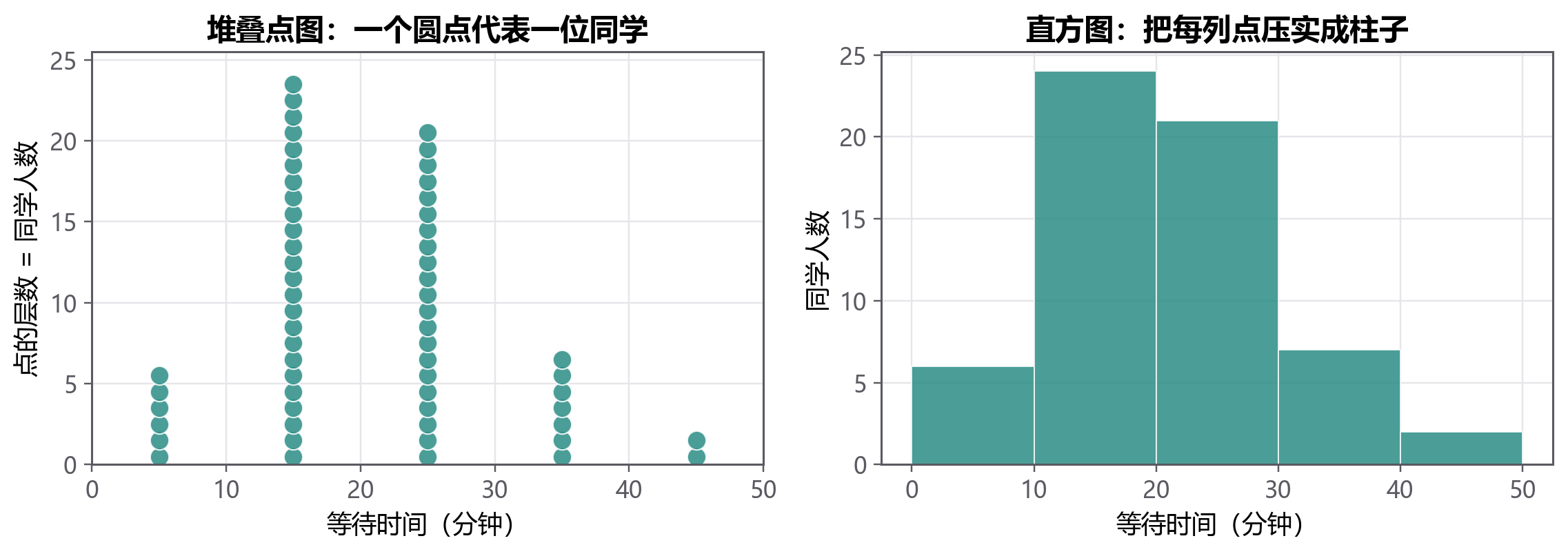
频数回答“有多少个”,频率回答“占多大比例”。两者都要会看:
- 如果你关心店员实际要处理多少人,频数更直观。
- 如果你想比较不同天、不同店、不同班级,频率更公平。
比如今天调查 60 人,明天调查 120 人,只比较频数会受样本量影响;换成频率,才能看出“比例结构”有没有变化。
2.3.2 直方图讲的是分布形状¶
直方图(Histogram) 用相邻柱子表示数值变量在不同区间里的频数或频率。
看直方图时,先看四件事:
- 中心:数据大致集中在哪里。
- 离散:数据 spread 得有多宽。
- 形状:对称、右偏、左偏、双峰,还是很奇怪。
- 异常:有没有远离主体的点或区间。
先画图,再算数
平均值、标准差、中位数都只是压缩后的数字。直方图能先告诉你:这组数据适不适合被压成一个数字。
看直方图时,不要只问“最高柱子是哪一个”。更好的读法是从左到右讲一遍故事:
大多数同学等了 10 到 30 分钟;超过 40 分钟的人很少;整体右边稍微拖尾;如果要改善体验,可能重点不是平均等待时间,而是减少少数特别久的等待。
这就是“分布(Distribution)”这个词的意思:不是一个单独的数,而是所有取值怎样铺开。
2.3.3 组距会改变你看到的故事¶
直方图需要先选区间宽度,也叫 组距(Bin Width)。组距太宽,细节会被抹平;组距太窄,随机噪声会被放大。
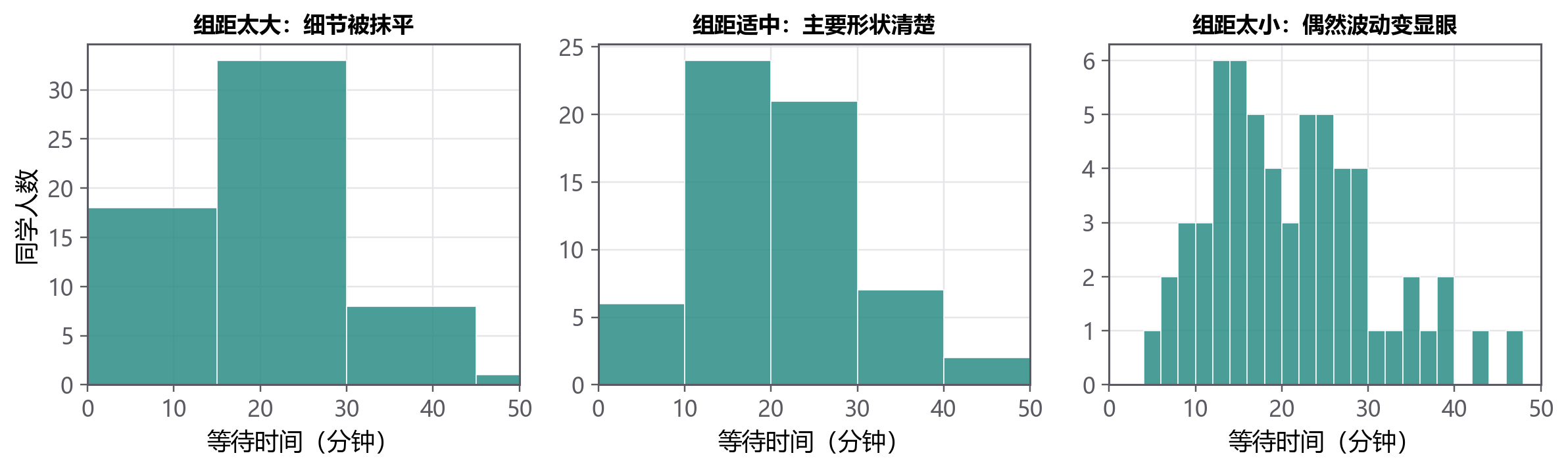
常见做法是先用软件默认值或经验规则,再检查结果是否稳定。对初学者来说,最重要的不是背规则,而是知道:直方图不是唯一真相,它是带有选择的视角。
一个稳妥做法是多试几种合理组距:比如 5 分钟、10 分钟、15 分钟。如果结论在不同组距下都差不多,说明形状比较稳定;如果换个组距故事就变了,报告时就要更谨慎,最好同时给出原始点图或箱线图。
2.3.4 累计频率回答“低于某个值有多少”¶
有时我们不只关心每个区间有多少,还关心“低于某个值的比例”。
比如社团想知道:等待时间不超过 30 分钟的同学占多少?这时要看 累计频率(Cumulative Relative Frequency)。
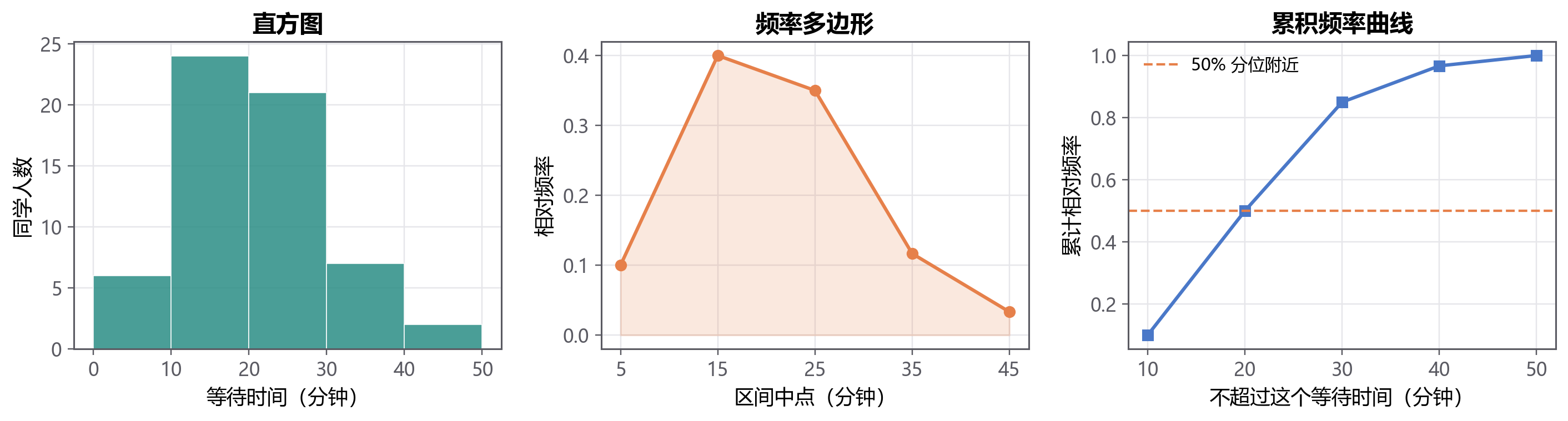
累计频率的典型问题包括:
- 低于某个阈值的比例是多少?
- 前 25%、50%、75% 分别落在哪里?
- 某个观察值处在整体中的什么位置?
这些问题会自然通向第 2.7 节的四分位数和箱线图。
累计频率在生活里特别常见。电商平台会说“90% 的订单在 48 小时内送达”,这就是一个累计频率式的表达;考试成绩里说“你的成绩超过了 82% 的同学”,也是在说你位于整体的哪个累计位置。
2.3.5 频率不是概率,但会靠近概率¶
频率来自样本,概率描述长期规律或总体机制。样本量很小时,频率会抖动;样本量变大后,频率通常更稳定。
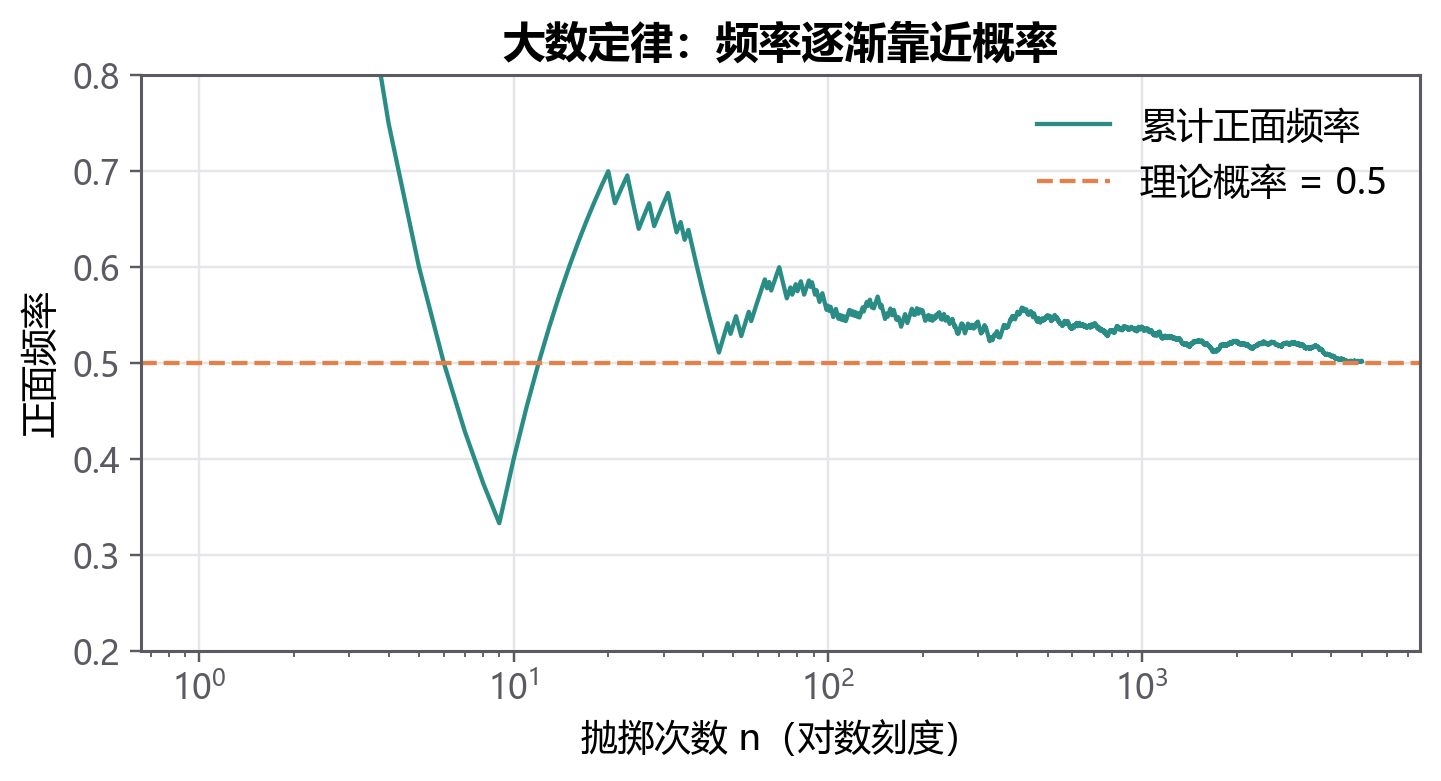
比如这 60 位同学里,等待超过 30 分钟的比例是 15%。这只是这次调查的频率。它不等于“这家店未来每一天等待超过 30 分钟的概率一定是 15%”。如果调查时间换成周一上午,比例可能变小;如果换成周末下午,比例可能变大。
所以频率是观察结果,概率是我们试图理解的长期机制。第三章会继续往下走:当我们反复观察随机现象时,频率为什么会围绕某个规律波动?
2.3.6 用 Python 做频数表和直方图¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
wait_time = np.array([
5, 6, 7, 8, 9, 9,
10, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16,
17, 17, 18, 18, 19, 19, 11, 12, 13, 14, 15, 16,
20, 21, 22, 22, 23, 23, 24, 24, 25, 25, 26, 26,
27, 27, 28, 28, 29, 29, 21, 23, 25,
31, 32, 34, 35, 36, 38, 39,
42, 46,
])
bins = [0, 10, 20, 30, 40, 50]
groups = pd.cut(wait_time, bins=bins, right=False)
freq = groups.value_counts().sort_index()
table = pd.DataFrame({
"频数": freq,
"频率": freq / len(wait_time),
"累计频率": (freq / len(wait_time)).cumsum(),
})
print(table)
fig, ax = plt.subplots(figsize=(7, 4))
ax.hist(wait_time, bins=bins, edgecolor="white", color="#27948e")
ax.set_xlabel("等待时间(分钟)")
ax.set_ylabel("同学人数")
ax.set_title("奶茶等待时间的直方图")
ax.set_xticks(bins)
plt.tight_layout()
plt.show()
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/03_frequency_and_distribution.py,可以复现频数表、直方图和累计频率图。
小率的笔记本
- 频数是某个类别或区间出现的次数,频率是频数除以样本量。
- 直方图用区间展示数值变量的分布形状。
- 组距会改变图形细节,不能随便挑一个“最好看”的图。
- 累计频率回答“低于某个值的比例是多少”。
- 频率是样本中看到的比例,概率是更深层的长期规律。
- 读分布时要同时看中心、宽度、尾巴和异常值,不要只盯最高柱。