2.5 中位数与众数¶
小率在咖啡店刷到一条新闻:“本市应届生平均月薪 9 800 元。”
他抬头看向均哥。
均哥没有立刻回答,而是在纸上写下一串月薪:

这就是本节要解决的问题:当少数极端值把平均数拉远时,我们还可以怎样描述一组数据的典型水平?
答案通常有两个朋友:中位数(Median)和众数(Mode)。
如果说均值像“把总量平均分摊”,中位数更像“排队时站在正中间的人”,众数更像“最多人选择的那个答案”。它们都在描述中心,但中心不只有一种含义。
2.5.1 先把数据排好队¶
中位数的第一步不是计算,而是排队。
把数据从小到大排好:
这组数据有 10 个数,正中间没有单独一个人,而是第 5 个和第 6 个站在中间:
所以中位数是这两个数的平均:
小率一下明白了。
这里的“排队”非常关键。中位数不关心每个数离它有多远,只关心左右两边各有多少个数。一个特别高的工资会把均值拉走,但只要它还站在队伍最右边,中间位置就不会变。
2.5.2 中位数:更适合描述“典型的人”¶
中位数(Median) 是排序后位于中间位置的数。
如果数据个数是奇数,中位数就是正中间那个数:
中位数是 20。
如果最后一个数从 80 变成 800:
中位数仍然是 20。
这就是中位数的稳健性(Robustness):少数特别大或特别小的值,不会轻易改变它。
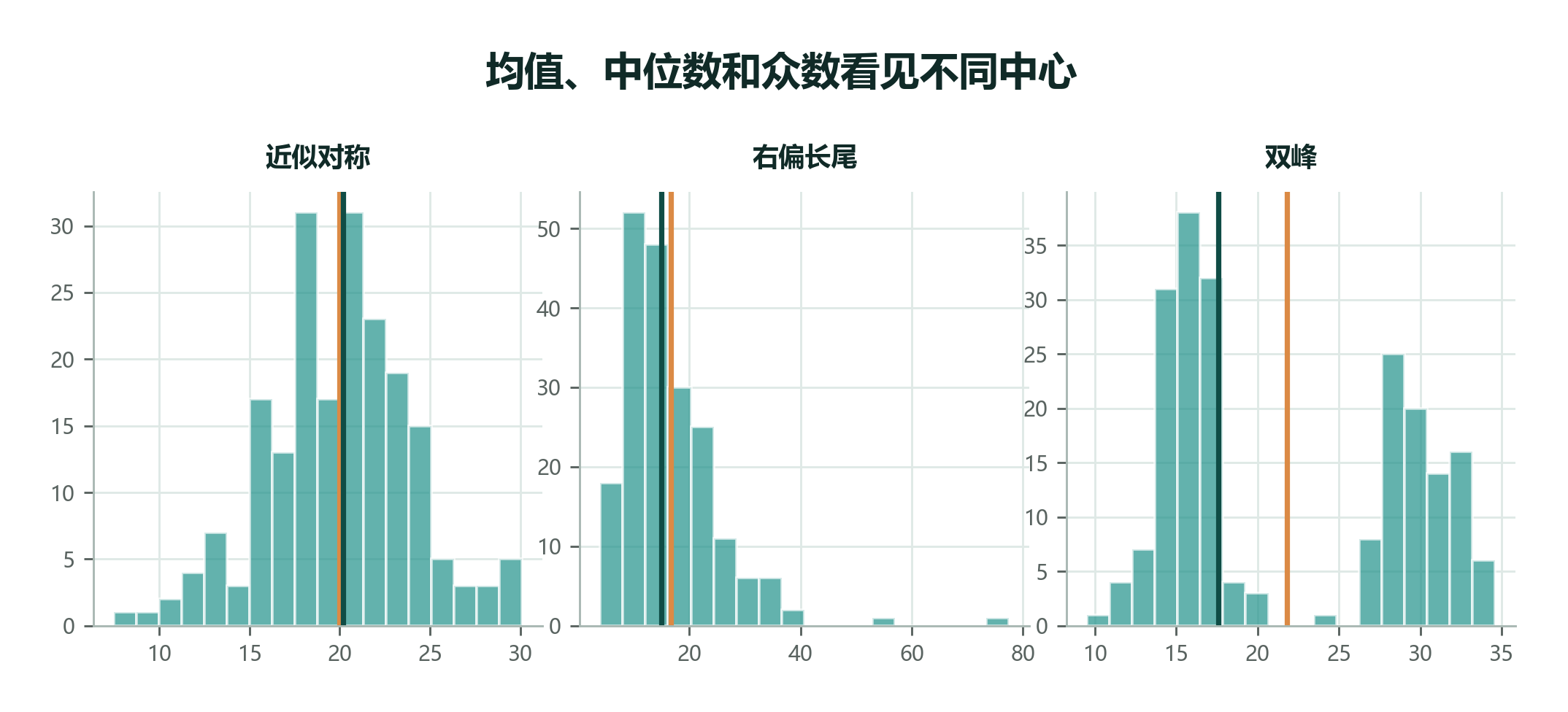
什么时候优先看中位数
工资、房价、医疗费用、网页点击数、外卖等待时间这类数据,常常右侧拖着长尾。此时中位数通常比均值更接近“大多数人的典型体验”。
中位数还有一个很实用的读法:它把人群分成两半。月薪中位数 5750 元,意思不是“大家都差不多拿 5750”,而是“大约一半人低于它,一半人高于它”。这比“平均月薪 8880 元”更接近普通读者在找工作时想知道的问题。
2.5.3 为什么“平均月薪”会让人误会¶
回到那条新闻。假设 10 个人的月薪如上:
| 人 | 月薪(元) |
|---|---|
| A | 3 800 |
| B | 4 200 |
| C | 4 500 |
| D | 5 000 |
| E | 5 500 |
| F | 6 000 |
| G | 6 800 |
| H | 8 000 |
| I | 10 000 |
| J | 35 000 |
均值是:
但中位数是 5750。
这两个数都没有“错”。它们只是回答了不同问题:
| 指标 | 回答的问题 | 在这个例子里的感觉 |
|---|---|---|
| 均值 | 如果把总收入平均分,每人是多少 | 被 35 000 明显拉高 |
| 中位数 | 排在正中间的人大约是多少 | 更接近多数人的体验 |
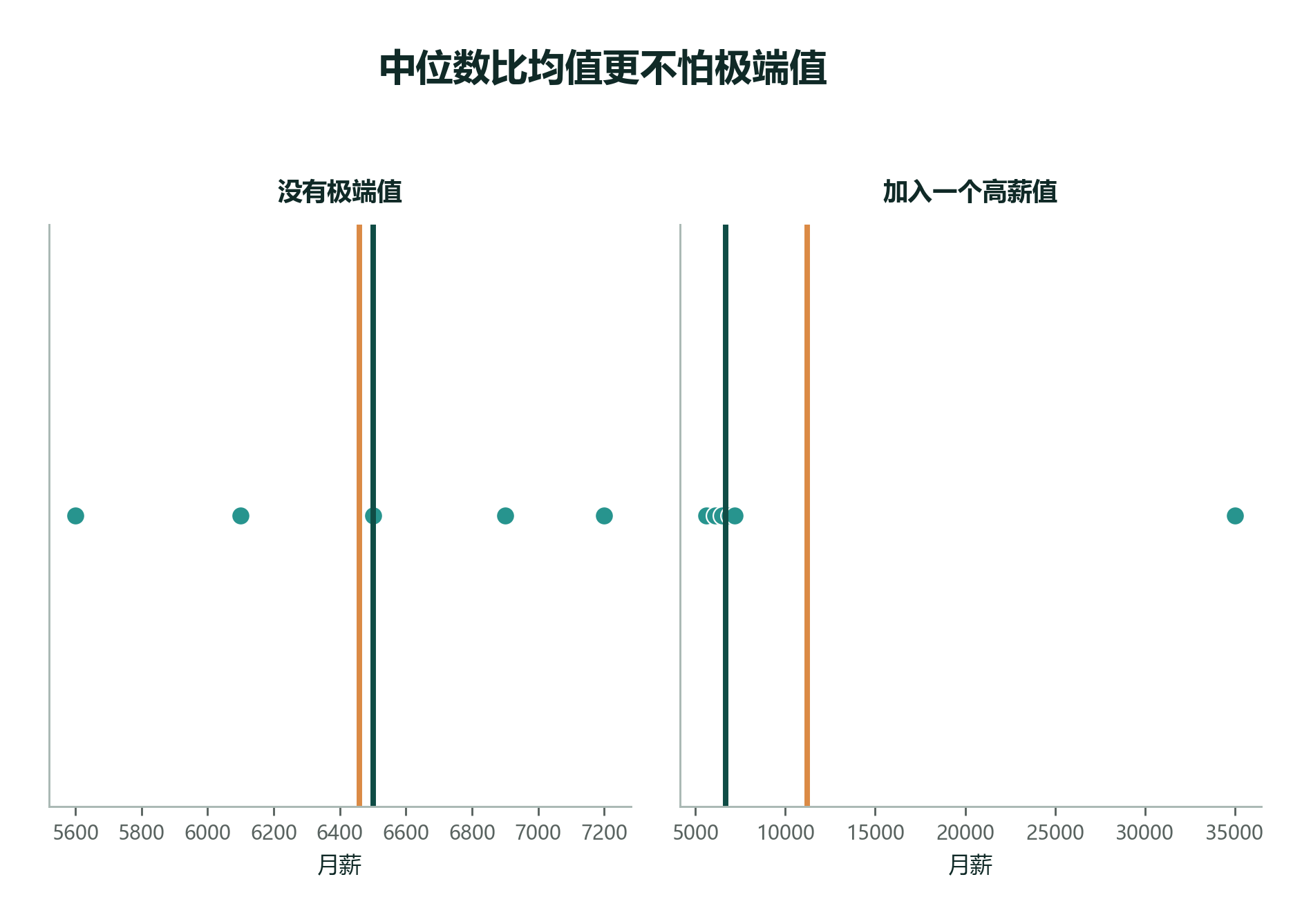
平均数不是谎言,但可能不完整
看到“平均工资”“平均房价”“平均消费”时,不要马上以为它代表普通人。最好同时问:中位数是多少?分布是不是右偏?有没有少数极端值?
很多公开报告会同时给出均值和中位数。两者差得不多时,说明分布可能比较对称;均值明显高于中位数时,往往提示右侧有长尾;均值明显低于中位数时,往往提示左侧有一些特别小的值。
这并不是说中位数永远比均值好。均值关心总量,中位数关心位置。公司算总薪酬成本时,均值很有用;求职者想知道普通岗位的薪资体验时,中位数更有用。
2.5.4 众数:出现最多的选择¶
有些数据根本不适合求平均。
比如小率整理班级社团报名表:
| 社团兴趣 | 人数 |
|---|---|
| 篮球 | 46 |
| 绘画 | 14 |
| 合唱 | 12 |
| 编程 | 9 |
你不能说“平均社团是 20.25”。这句话没有意义。
这时要看 众数(Mode):出现次数最多的取值。
在这个例子里,众数是“篮球”。
众数特别适合分类数据:
- 最受欢迎的奶茶口味。
- 最常见的通勤方式。
- 投票中选择最多的选项。
- 问卷里出现最多的满意度等级。
众数也适合回答“备货”和“选择”问题。奶茶店要决定哪种口味多备一点,学校要决定哪个社团需要更大教室,产品经理要看用户最常用的入口,众数都比均值自然得多。
不过众数也有局限:有些数据没有明显众数,有些数据有多个众数。比如两个社团报名人数并列第一,就会出现双众数;如果每个选项人数都差不多,众数虽然存在,却不一定有多强的代表性。
众数要看领先幅度
“篮球 46 人、绘画 14 人”时,众数很有解释力;“篮球 21 人、绘画 20 人、合唱 19 人”时,众数仍是篮球,但优势很弱,报告时应说明差距不大。
2.5.5 双峰数据别急着压成一个中心¶
有时,数据里会出现两个明显高峰。
比如到校时间:一批同学 7:30 左右到,另一批 8:05 左右到。你如果只报一个均值,说“大家平均 7:48 到”,反而会掩盖真实结构。
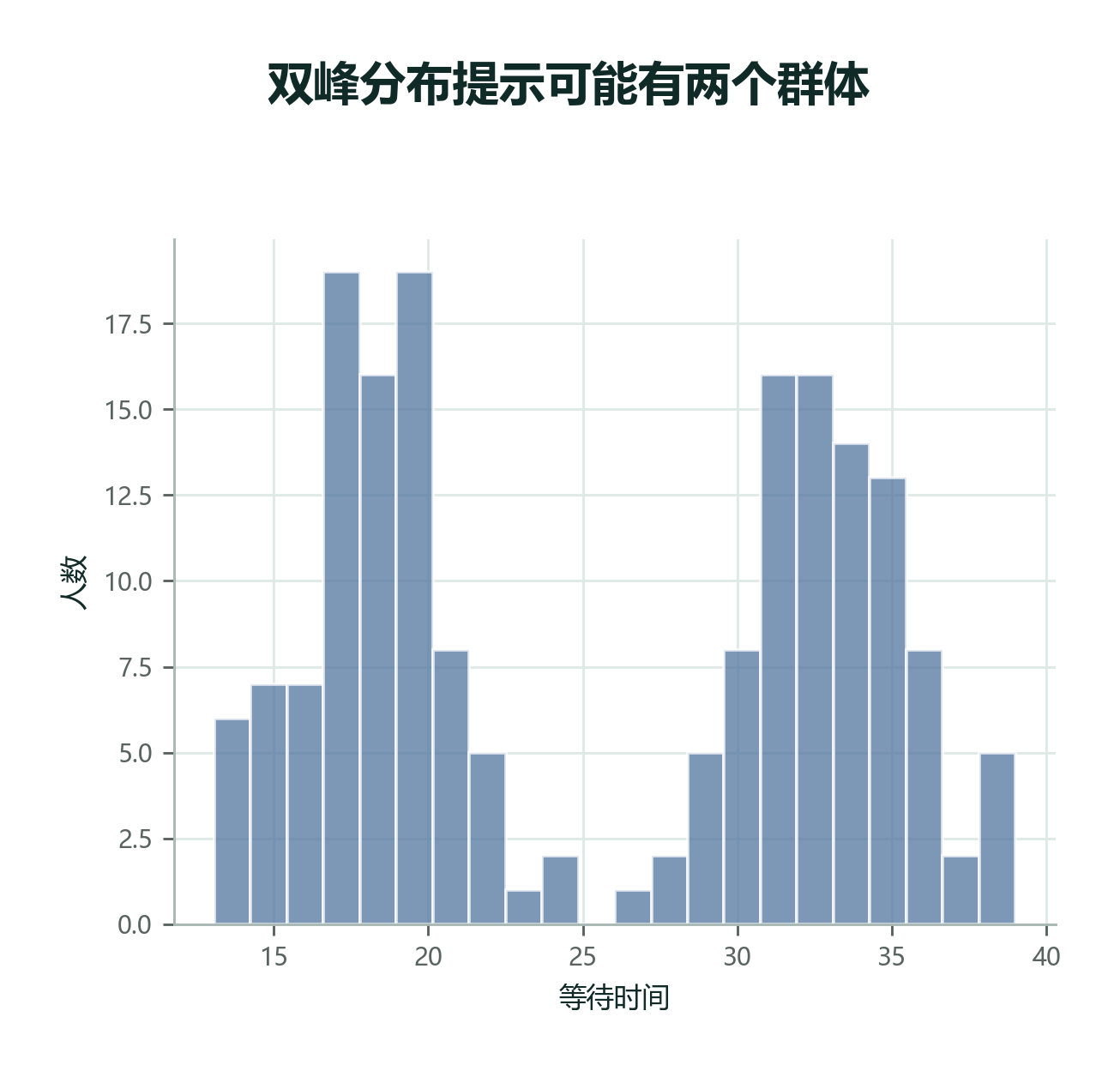
遇到双峰或多峰数据,先不要急着选均值、中位数或众数。更好的做法是:
- 先画图。
- 看看是不是混合了不同群体。
- 必要时分组描述。
一个中心值不是万能摘要
如果数据明显有两个高峰,只报一个中心值会让读者误以为“大家都差不多”。描述统计的任务不是把复杂数据强行压扁,而是把结构说清楚。
双峰数据经常在“混合人群”里出现。到校时间有两个高峰,可能是走读生和住宿生混在一起;消费金额有两个高峰,可能是普通用户和会员用户混在一起;运动成绩有两个高峰,可能是男女生或训练组与非训练组混在一起。
遇到这种形状,最好的下一步往往不是继续算中心,而是回到变量:有没有一个分组变量能解释这两个峰?如果有,分组描述会比整体均值诚实得多。
2.5.6 用 Python 计算中位数和众数¶
import numpy as np
import pandas as pd
salary = np.array([3800, 4200, 4500, 5000, 5500, 6000, 6800, 8000, 10000, 35000])
clubs = pd.Series(["篮球", "绘画", "篮球", "合唱", "篮球", "编程", "绘画"])
print(f"均值 = {salary.mean():.1f}")
print(f"中位数 = {np.median(salary):.1f}")
print(f"众数 = {clubs.mode().iloc[0]}")
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/05_median_and_mode.py,可以复现中位数稳健性和众数示例。
小率的笔记本
- 中位数是排序后站在中间的数,适合描述工资、房价、等待时间这类容易右偏的数据。
- 众数是出现最多的取值,特别适合分类数据。
- 均值、中位数、众数都不是“唯一正确答案”,它们回答的是不同问题。
- 看到双峰数据,先画图,再考虑是否应该分组描述。
- 选择中心指标前,先问:我关心总量分摊、典型位置,还是最多选择?