11.3 聚类分析¶
社区活动室里,小率把同学们的兴趣问卷贴满桌面:有人爱运动,有人爱熬夜打游戏,有人每天阅读很久。没有任何“标准答案”,但他想把相似的人自然分成几组。

没有标签,也没人告诉我谁属于哪组,这还能分析吗?
能。聚类就是在无标签数据里,让相似对象靠在一起。
11.3.1 聚类先定义什么叫相似¶
聚类分析(Cluster Analysis)要解决的问题是:把样本分成若干组,让组内尽量相似,组间尽量不同。
最先要定的是距离:
| 距离 | 适合数据 | 直觉 |
|---|---|---|
| 欧氏距离 | 连续变量、球形簇 | 两点直线距离 |
| 曼哈顿距离 | 高维、偏离群 | 沿网格走路 |
| 余弦距离 | 文本、方向相似 | 看方向不看长度 |
| Jaccard 距离 | 标签集合 | 看共同元素比例 |
聚类前先标准化
如果一个变量是“月消费金额”,另一个变量是“登录天数”,不标准化会让金额主导距离,聚类结果几乎变成按钱分组。
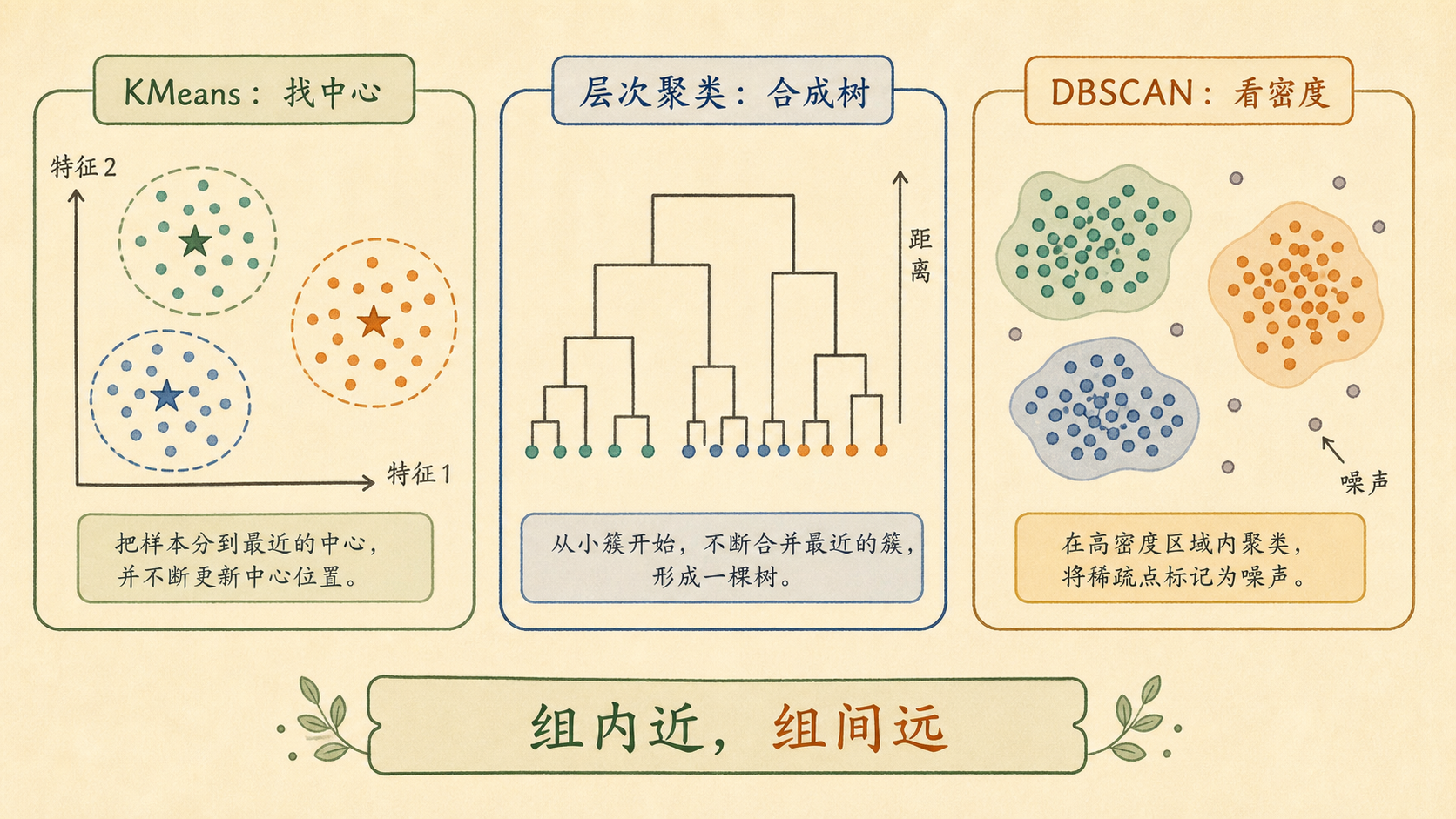
11.3.2 KMeans:先定中心再抢点¶
KMeans 假设簇大致像圆球。它先放 \(K\) 个中心,再重复两步:
- 每个点归到最近的中心。
- 每个中心移动到本组点的均值。
目标函数是最小化簇内平方和:
\[
\min \sum_{k=1}^{K}\sum_{x_i\in C_k}\|x_i-\mu_k\|^2
\]
所以 KMeans 喜欢“圆圆的一团”,不太会处理月牙形?
正是。算法的偏好就是它的边界。
11.3.3 层次聚类:把分组画成一棵树¶
层次聚类(Hierarchical Clustering)从每个点自己一组开始,逐步合并最近的组,最后得到一棵树状图。你可以在树上切一刀,得到任意数量的簇。
常见 linkage:
ward:合并后组内方差增加最小,常用。complete:看两组之间最远点。average:看平均距离。single:看最近点,容易产生长链。
什么时候用
样本量不大、想看层级结构时,层次聚类很适合。样本几十万时,它通常太慢。
11.3.4 DBSCAN:哪里点密,哪里就是一群¶
DBSCAN 根据密度找簇。它需要两个参数:
- \(\varepsilon\):邻域半径。
min_samples:邻域内至少多少个点才算密集。
点分三类:
- 核心点:邻域里点足够多。
- 边界点:靠近核心点,但自己不够密。
- 噪声点:不属于任何密集区域。
DBSCAN 的好处是能找到弯曲形状,还能标记噪声;缺点是参数敏感,而且不同密度的簇不好同时处理。
11.3.5 怎么选 K¶
KMeans 必须先给 \(K\)。常用方法:
| 方法 | 看什么 | 局限 |
|---|---|---|
| 肘部法 | 簇内平方和下降是否变慢 | 肘部不一定明显 |
| 轮廓系数 | 组内近、组间远的综合分 | 高维时可能不稳定 |
| 业务解释 | 分出的组是否能命名 | 需要领域判断 |
轮廓系数(Silhouette)范围是 \([-1,1]\),越大通常越好。
如果轮廓系数高,但分出来的组讲不出意义呢?
那仍然不能用。聚类最后要回到人能理解的分组。
11.3.6 用 Python 比较三种聚类¶
完整脚本放在:
from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
X, _ = make_blobs(n_samples=300, centers=3, random_state=42)
X = StandardScaler().fit_transform(X)
kmeans = KMeans(n_clusters=3, n_init=10, random_state=42).fit(X)
hier = AgglomerativeClustering(n_clusters=3, linkage="ward").fit(X)
db = DBSCAN(eps=0.45, min_samples=5).fit(X)
for name, labels in [
("KMeans", kmeans.labels_),
("层次聚类", hier.labels_),
("DBSCAN", db.labels_),
]:
valid = labels != -1
score = silhouette_score(X[valid], labels[valid]) if len(set(labels[valid])) > 1 else float("nan")
print(name, "簇标签:", sorted(set(labels)), "轮廓系数:", round(score, 3))
小率的笔记本
聚类没有标准答案。先标准化,再定义距离,再选算法。KMeans 快但偏爱球形簇;层次聚类能看嵌套结构但慢;DBSCAN 能找任意形状和噪声,但参数敏感。最后一定要检查分组能不能解释。