8.6 多项式回归¶
本节学习目标
- 用 多项式特征 处理非线性关系
- 理解 欠拟合 / 过拟合 的偏差-方差权衡
- 掌握 样条 (Splines) 与 ** 分段拟合** 思路
8.6.1 反应速率的倒 U 形曲线¶
化工实验员盯着一组数据发呆:横轴是 反应温度 ** (20 °C 到 80 °C),纵轴是 ** 反应速率 ** 。 直观一看:低温慢、中温最快、高温反而下降——速率随温度先升后降,呈一个明显的 ** 倒 U 形 。
工程师习惯性掏出 OLS 拟合一根直线:\(\hat{y} = a + bx\),结果 \(R^2 = 0.21\),残差画出来呈完美的 U 形。 模型说『温度对速率没什么影响』,可肉眼一看明明就有强非线性关系——直线根本无法穿过这堆点的中央骨架。
故事的核心问题: 当真实关系是曲线时,怎么继续用回归框架? 上一节诊断里我们说『残差 U 形 → 加非线性项』,本节就把这件事做细——** 多项式回归 ** 是最朴素的解,** 样条 ** 是更稳的解,** LOWESS / GAM** 是更灵活的解,三者都建立在同一个核心思想上。
8.6.2 拼直尺:偏差-方差的旋钮¶
把『非线性』想成『拼直尺』:直线拟合是只允许用 一根 直尺;二次拟合允许尺子弯一下,刚好能拼一个抛物线;三次拟合允许尺子拐两次,能勾出 S 形或多峰;阶数越高,尺子越花哨。
但 花哨是有代价的 ** 。 阶数太低,尺子根本贴不上数据骨架—— 欠拟合 ** ,模型有偏差;阶数太高,尺子能钻进每个数据点甚至噪声里——** 过拟合** ,模型方差暴涨。 中间的某个 d 才是甜蜜点。
下面的动画把这件事变成一个滑块:拖动多项式阶数 \(d\),蓝色拟合曲线实时变化,下方训练 MSE 与测试 MSE 同步显示。 你会看到二者先 一起下降 ** (\(d\) 从 1 到 3,模型变好),再 ** 分叉 ** (\(d > 5\),训练继续降但测试反弹)。 那个交叉点就是 ** 偏差-方差权衡 的视觉化。
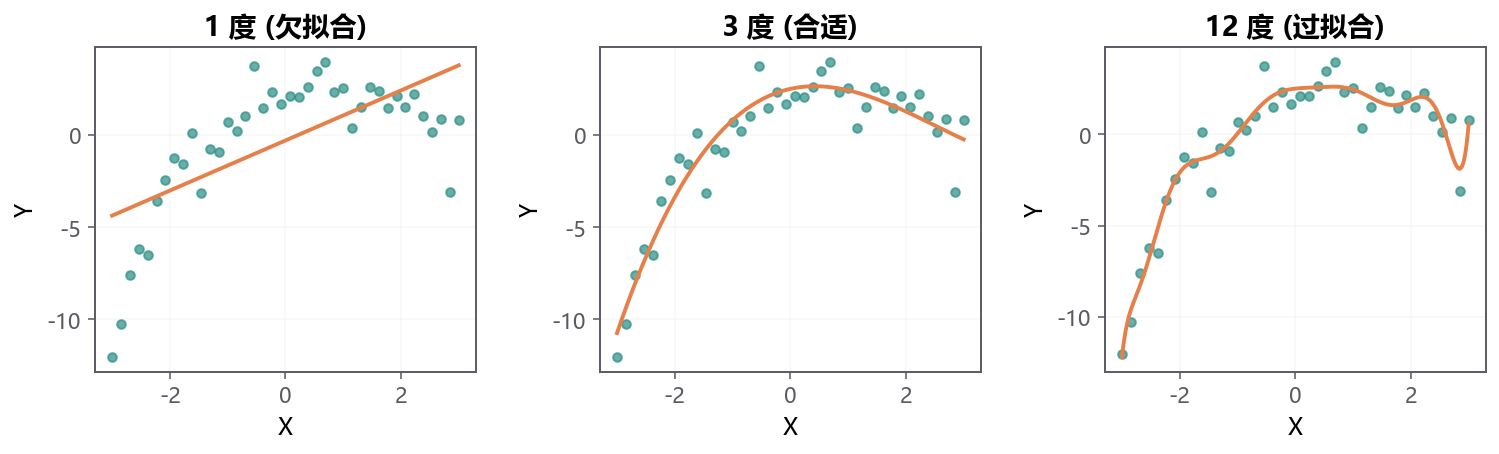
注意动画里 \(d = 10\) 的曲线 在边界附近剧烈摆动 ** ——这有个名字叫 ** Runge 现象 ,是高次多项式的招牌病。
8.6.3 把 \(X^k\) 当新特征塞进 OLS¶
把直线 \(y = \beta_0 + \beta_1 x\) 升级成 \(d\) 次多项式:
关键洞察:模型仍然 关于参数 \(\boldsymbol{\beta}\) 线性 ** ,因此可以照搬 OLS 的全部机器——把 \(X^2, X^3, \dots, X^d\) 当成新的『特征列』填进设计矩阵 \(\mathbf{X}\),然后跑 \(\hat{\boldsymbol{\beta}} = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y}\) 即可。 这就是『 对参数线性,对变量非线性** 』的精髓。
阶数 d 的选择:偏差-方差权衡¶
- \(d\) 太低 → 欠拟合 :系统性偏差,残差图呈 U 形
- \(d\) 太高 → 过拟合 :训练好测试差,且边界 Runge 震荡
- 选最佳 \(d\) 的标准答案: 交叉验证 (CV),看哪个 \(d\) 让验证 MSE 最小
8.6.4 Runge 现象¶
高次多项式在区间端点附近 剧烈震荡 ——即使训练点处拟合完美,端点外的预测也是灾难。 数学家 Carl Runge 1901 年最早用 \(f(x) = 1/(1+25x^2)\) 在 \([-1, 1]\) 上做等距插值,d 越高震荡越夸张,故得名。
实战避坑:
- 限制 \(d \leq 3\) 或 \(4\) :日常曲线已够用
- 正交多项式基 (
np.polynomial.polynomial.polyfit):数值稳定,避免 \(X, X^2, X^3\) 高度共线 - 用样条代替 :分段低次胜过整段高次
8.6.5 样条与 LOWESS¶
样条 (Splines) :把 \(X\) 域分段,每段拟合低次(常用 3 次)多项式, ** 节点 (knot)** 处保证函数与一阶/二阶导数连续。 这样既灵活又不震荡。
- 自然三次样条 :在边界外强制为线性,避免外推爆炸
- B-spline / 平滑样条 :在 OLS 损失上加平滑惩罚
scipy.interpolate.UnivariateSpline 一行搞定。
局部加权回归 LOWESS :每个预测点用其周围数据加权(高斯权)拟合一条直线。 灵活、不需选 \(d\),但耗算力,常用于探索性可视化:
多元情形 有更高级的家族:
- 交互:\(X_1 X_2\)
- 二次面:\(X_1^2, X_2^2, X_1 X_2\)
- GAM (广义可加模型) :\(Y = \beta_0 + \sum_j f_j(X_j)\),每个 \(f_j\) 是平滑函数,兼具灵活与可解释
8.6.6 温度 vs 反应速率¶
回到化工实验员的数据:
- 直线 \(\hat{y} = a + bx\):\(R^2 = 0.21\),残差呈完美 U 形 → 欠拟合
- 二次 \(\hat{y} = a + bx + cx^2\):\(R^2 = 0.89\),残差变随机;\(c < 0\) 显著(开口向下,对应『先升后降』);F 检验大幅改善
模型可解释性也跟着提升:\(c\) 的符号告诉化学家 存在最优温度 ,对 \(\hat{y}\) 求导置 0 还能算出最优温度的位置(约 50 °C)——一个 \(X^2\) 项,把『随便拟合』升级成『工程优化』。
应用场景
剂量-效应曲线(药效随剂量先升后降)、农业产量 vs 施肥量(U 形)、广告投入 vs 销量(边际递减)、电池循环寿命 vs 温度、芯片良率 vs 蚀刻时间——任何『有最优值』或『有拐点』的工程问题,多项式(或样条)回归比线性回归告诉你的多得多。
8.6.7 用交叉验证自动选阶数 d¶
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score
rng = np.random.default_rng(0)
n = 60
x = np.linspace(-3, 3, n)
y = 2 + 0.5*x - 0.8*x**2 + 0.15*x**3 + rng.normal(0, 1, n)
# 用 CV 选 d
for d in [1, 2, 3, 5, 10]:
pipe = make_pipeline(PolynomialFeatures(d), LinearRegression())
cv = cross_val_score(pipe, x.reshape(-1,1), y, cv=5,
scoring='neg_mean_squared_error')
print(f"d={d:2d} CV-MSE = {-cv.mean():.3f}")
跑出来你会发现 \(d = 3\) 的 CV-MSE 最小(真实生成机制就是 3 次),\(d = 10\) 反而变差——CV 自动地把 偏差-方差 量化成一个数字,让你不用肉眼看图就能选阶数。
8.6.8 居中、正交基与外推禁忌¶
- \(d = 2\) 或 \(3\) 通常已够用;想要更灵活, 优先样条 / GAM 而不是更高次多项式
- 拟合前 居中 (减均值)或用正交多项式基,避免 \(X, X^2, X^3\) 高度共线把数值条件搞坏
- 高次相关严重 → VIF 爆炸 → 用正则化(§8.7)或正交基
- 永远画图 :拟合曲线 + 残差图,一张都不能少
陷阱:用高次多项式做外推
Runge 现象在样本端点之外更恐怖。 拟合温度 20–80 °C 的速率,模型在 100 °C 处可能预测出负值。 多项式回归的有效区间 只在数据范围之内 ;外推请慎之又慎,或换用样条 + 边界约束。
你知道吗
Runge 1901 年构造的反例 \(f(x) = 1/(1+25x^2)\) 至今仍是数值分析教材的标配。 它的存在直接导致 19 世纪末插值领域转向 分段方法 ** (样条),并最终孕育了今天 CAD、动画、字体设计里无处不在的 ** Bézier 曲线 与 B-spline。 一个小反例改变了整个工程图形学的走向。
8.6.9 本节小结¶
- 多项式回归 = 把 \(X^k\) 当新特征塞进 OLS, 对参数线性、对变量非线性 ,机器照旧。
- 阶数 \(d\) 是 偏差-方差 的旋钮:太低欠拟合,太高过拟合 + Runge 震荡。
- 用 CV 选 d ;\(d > 3, 4\) 通常该改用 ** 样条 / GAM / LOWESS** 。
- 永远画拟合曲线 + 残差,不要外推到数据范围之外。
- 下节 §8.7 用 正则化 系统性地控制过拟合,给所有回归装上『防摆动护栏』。