8.7 正则化¶
本节学习目标
- 理解 正则化 与偏差-方差权衡
- 掌握 Ridge (L2) 与 Lasso (L1)
- 知道 Elastic Net 与 ** 早停**
- 用 CV 选 λ
8.7.1 \(p = 10000, n = 100\) 的基因组困境¶
某基因组学实验室收集了 100 位患者,每位测了 10000 个基因表达值,想预测一种疾病的进展速度。 数学上他们要解一个 \(p = 10000, n = 100\) 的回归——特征比样本多一百倍 。
数据科学家照常喂给 OLS——np.linalg.solve(X.T @ X, X.T @ y) 直接抛出 LinAlgError: Singular matrix,矩阵不可逆。 即使勉强加点扰动算出『解』,每个 \(\hat{\beta}_j\) 的方差都大到没意义——同样的实验重做一次,挑出来的『关键基因』可能完全不一样。 OLS 在 \(p > n\) 或 多重共线 的世界里直接崩溃。
更糟的场景在小样本里也常见:100 个变量 30 个样本拟合,训练 \(R^2 = 0.99\),测试 \(R^2 = 0.3\)——典型的 过拟合 ** 。 故事的核心问题: 怎么让回归在变量比样本多、或彼此高度相关时,依然给出稳定、有泛化能力的解? ** 答案是 ** 正则化** :在 OLS 损失上加一个『系数惩罚』,强迫系数变小或干脆归零。
8.7.2 给 OLS 学生加一句『扣分』¶
把 OLS 想成一个 只追求拟合好 的学生:他会把所有自由度用满,让训练误差降到最低——哪怕是去钻噪声的牛角尖。 正则化 = 给这个学生加一句话:『你拟合好我给你 1 分,但 每用一点系数大小 我扣你 \(\lambda\) 分。』于是学生开始斟酌:值不值得为这点 \(R^2\) 提升,付出系数膨胀的罚金?
同一句话,惩罚怎么算决定了模型的性格:
- Ridge(L2) ** :罚 \(\sum \beta_j^2\)。 系数被『软压』向 0,但 ** 永远不为 0 。 适合『许多变量都有点用』。
- Lasso(L1) ** :罚 \(\sum |\beta_j|\)。 系数会被 ** 压到精确等于 0 ,自动做特征选择。 适合『大量变量但只有少数真正有用』(高维稀疏)。
- Elastic Net :把 L1 和 L2 按比例混合。 兼具 Lasso 的选择能力和 Ridge 的稳定性,特别在『有一组高度相关变量都该一起留』时表现更好。
下面的动画把这三种性格并排展示:拖动 \(\lambda\),看 Ridge 平滑收缩 vs Lasso 依次归零的对比。
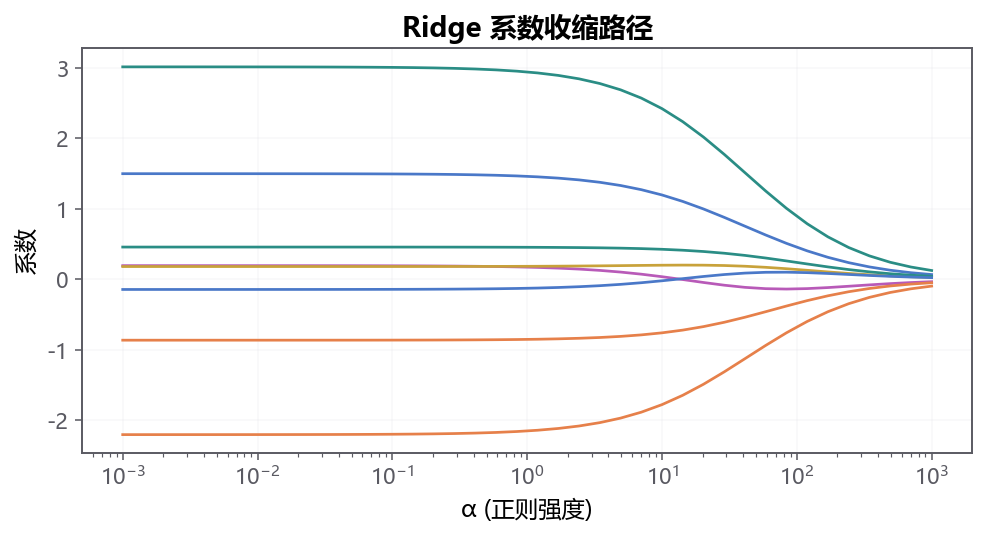
第二个直觉是 几何 :L1 的约束区域是 菱形 (有尖角),L2 是 圆形 。 OLS 的椭圆等高线撞上菱形最容易撞在 尖角 上——尖角对应某个 \(\beta_j = 0\),这就是 Lasso 自动归零的几何根源。 撞上圆形则总是 切 在某条边,所有 \(\beta\) 都非零但被压小。
8.7.3 Ridge、Lasso 与 Elastic Net 公式¶
Ridge (L2)¶
求导可得 闭式解 :
关键:\(\mathbf{X}^\top \mathbf{X} + \lambda \mathbf{I}\) 总是可逆 (只要 \(\lambda > 0\))——OLS 在 \(p > n\) 下崩溃的根源被一行公式根治。
- \(\lambda = 0\) → 退化为 OLS
- \(\lambda \to \infty\) → 全部系数趋 0
- 特点: 收缩但不归零 ,系数全部保留但都被压小
Lasso (L1)¶
无闭式解,靠 坐标下降 (coordinate descent) 或 LARS 算法迭代。 关键性质: ** 可使 \(\beta_j\) 精确 = 0** → 自动 ** 特征选择** 。
Elastic Net¶
\(\alpha = 1\) 退化为 Lasso,\(\alpha = 0\) 退化为 Ridge,中间值兼具两者优点。 高度共线变量组下,Lasso 容易『随机选一个』,Elastic Net 倾向把它们一起留。
8.7.4 标准化与 λ 选择¶
必做:特征标准化¶
正则化对 系数尺度 ** 敏感——如果一个特征是『年薪(万元)』范围 1–100,另一个是『身高(米)』范围 1.5–1.9,系数大小会被尺度扭曲,惩罚不公平。 ** 必须先把每列 X 减均值除标准差 。 sklearn 的标准搭配是 StandardScaler + Pipeline,记住这个习惯就不会出错。
选 λ:交叉验证 + 1-SE 规则¶
\(\lambda\) 是超参数,由 K 折交叉验证 选:训练 / 验证若干次,看哪个 \(\lambda\) 让验证 MSE 最小。
RidgeCV、LassoCV、ElasticNetCV 都自带 CV。 推荐进一步用 1-SE 规则 :在所有 \(\lambda\) 中,挑选 验证 MSE 不超过最优值 + 1 个标准误 的最简单(\(\lambda\) 最大、模型最简)的那个。 它能进一步压住过拟合,是 Hastie & Tibshirani 的经典推荐。
8.7.5 高维稀疏回归¶
回到引言的基因组场景,做一个简化版:100 个特征 50 个样本,但只有前 5 个真正有信号。 OLS 会爆方差;Lasso 应该能精确选出前 5 个:
import numpy as np
from sklearn.linear_model import Lasso, LassoCV, Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
rng = np.random.default_rng(0)
n, p = 100, 50
X = rng.normal(0, 1, (n, p))
true = np.zeros(p); true[:5] = [3, -2, 1.5, 1, -1]
y = X @ true + rng.normal(0, 1, n)
pipe = Pipeline([('sc', StandardScaler()),
('lasso', LassoCV(cv=5))])
pipe.fit(X, y)
beta = pipe.named_steps['lasso'].coef_
print(f"Lasso 选中 {(np.abs(beta) > 1e-6).sum()} / {p} 个变量 (真 5)")
print(f"前 5 个系数 (真 = 3, -2, 1.5, 1, -1):")
print(beta[:5])
print(f"最优 λ = {pipe.named_steps['lasso'].alpha_:.4f}")
跑出来 Lasso 通常会选 5–8 个变量(前 5 + 1, 2 个『近邻噪声』),剩下 40 多个被精确压到 0。 OLS 跑同样数据,每个 \(\hat{\beta}\) 的标准误可能比系数本身还大 ——这就是正则化的价值。
应用场景
高维基因组学(变量比样本多)、文本分类(词袋特征上万)、推荐系统(用户-物品矩阵稀疏)、金融风控(数百个候选指标)、广告 CTR(特征工程后特征数爆炸)——只要『候选变量很多但真正有用的少』,Lasso 几乎总值得一试;在变量都有点用且共线严重时,Ridge 或 Elastic Net 更稳。
8.7.6 与贝叶斯先验的联系¶
正则化在贝叶斯眼里就是『给 \(\beta\) 上先验』:
- Ridge ↔ Gaussian 先验:\(\beta_j \sim \mathcal{N}(0, \tau^2)\)
- Lasso ↔ Laplace 先验:\(\beta_j \sim \text{Laplace}(0, b)\)(双指数,尖峰重尾,鼓励稀疏)
最大化『后验密度』恰好等价于最小化 RSS + 惩罚项 ——也就是 MAP 估计 。 频率派的『正则化』和贝叶斯派的『先验』是同一件事的两个名字。 详见第 10 章贝叶斯。
8.7.7 什么时候用哪个?¶
| 情况 | 推荐 |
|---|---|
| 变量较少 + 都有用 | OLS / Ridge |
| 大量变量 + 少数有用 | Lasso |
| 高度共线变量组都该一起留 | Elastic Net |
| 想做特征选择 + 解释 | Lasso(再用选出的变量跑 OLS 得『post-Lasso』无偏估计) |
| 只关心预测精度 | 三者都跑 + CV 选最优 |
陷阱:正则化前不标准化
各变量尺度差异巨大时,惩罚自动倾向于罚『单位大的变量』,结果就是 单位米的特征活下来,单位毫米的特征被压死 ——结论完全是单位选择的偶然结果。 永远先 StandardScaler 。
你知道吗
Lasso 这个名字是 Tibshirani 1996 年起的,是 L east A bsolute S hrinkage and S election O perator 的首字母缩写。 这个『取首字母又恰好是个常见词』的命名传统在统计学里广泛传播——后来还有 LARS(最小角回归算法)、SCAD、MCP 等一脉相承的稀疏惩罚家族。 Tibshirani 这篇论文目前引用量超过 5 万次 ,是统计学史上被引最多的几篇之一。
8.7.8 本节小结¶
- OLS 在 \(p > n\) 或多重共线时崩溃;正则化用 系数惩罚 控制过拟合。
- Ridge (L2) 平滑收缩、闭式解、不归零; Lasso (L1) 稀疏选择、需迭代、可归零; Elastic Net 折中。
- 必须先 标准化 X ;用 CV + 1-SE 规则 选 \(\lambda\)。
- 频率派的正则化 ↔ 贝叶斯派的先验:Gaussian ↔ Ridge,Laplace ↔ Lasso。
- 下节 §8.8 给整章做总结,把回归族成员对照表呈上。