7.4 显著性概率值¶
小率在科学社团的展示板上看到两份报告:
| 报告 | p 值 | 结论 |
|---|---|---|
| A | 0.049 | 显著 |
| B | 0.051 | 不显著 |
两个数字只差 0.002,却被贴上完全不同的标签。小率觉得这很奇怪:难道 0.049 和 0.051 之间真的隔着一道科学分界线吗?

7.4.1 p 值是一块尾巴面积¶
p 值的定义是:
它总是在 \(H_0\) 的世界里算。若当前统计量落在分布尾部,尾巴面积小,p 值就小;若当前统计量不算极端,尾巴面积大,p 值就大。
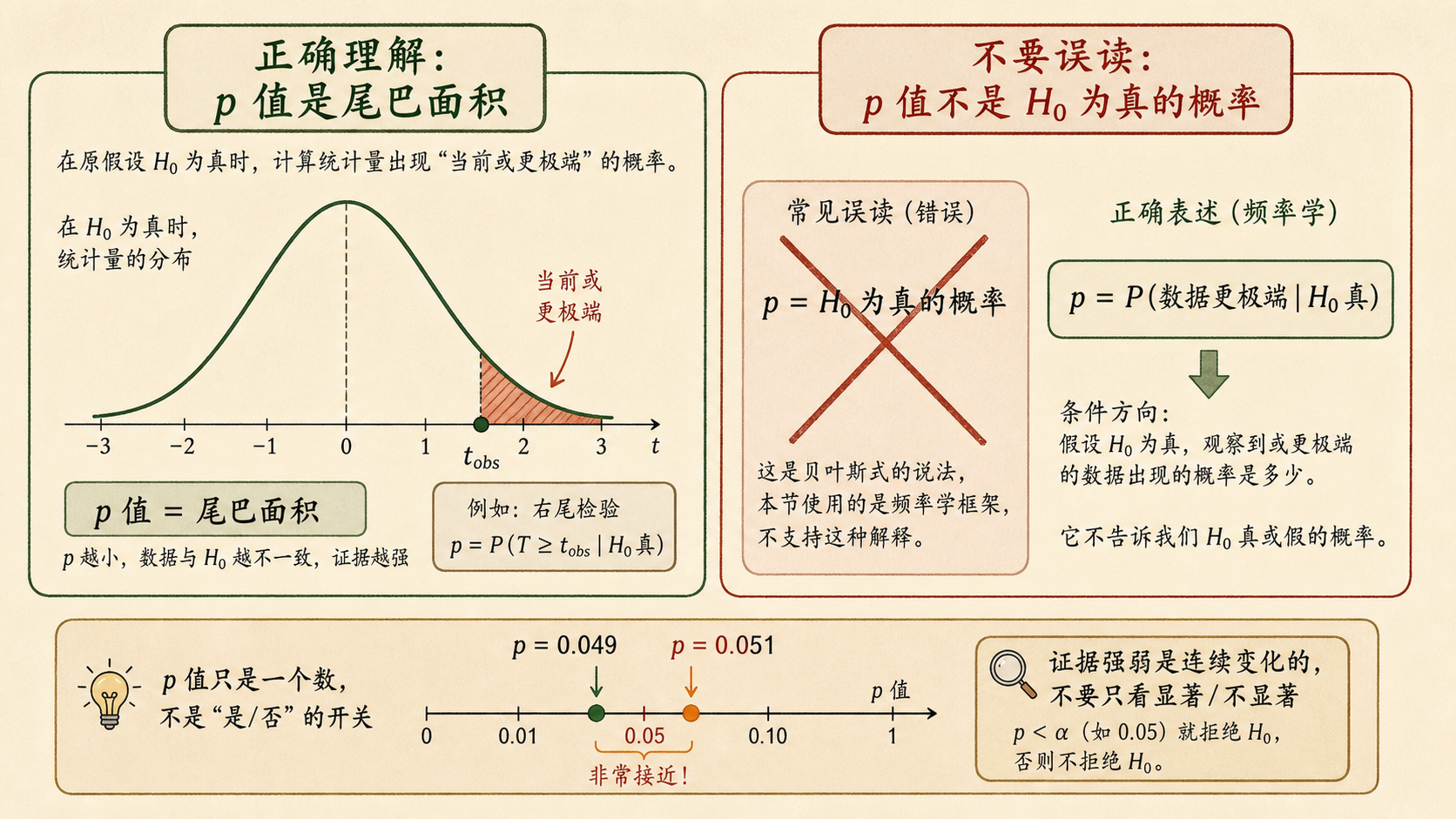
把 p 值翻译成人话
p 值小:如果 \(H_0\) 真的成立,这种结果不太常见。
p 值大:如果 \(H_0\) 真的成立,这种结果并不奇怪。
7.4.2 p 值不是 H0 为真的概率¶
最常见的误读是:
p=0.03,所以 \(H_0\) 为真的概率是 3%。
这是错的。p 值是:
不是:
这两个条件方向完全不同。若想讨论“假设为真的概率”,需要贝叶斯框架和先验概率。
7.4.3 p 值和 alpha 如何配合¶
显著性水平 \(\alpha\) 是实验前设好的阈值。决策规则是:
| 比较 | 决策 |
|---|---|
| \(p<\alpha\) | 拒绝 \(H_0\) |
| \(p\ge\alpha\) | 不拒绝 \(H_0\) |
但 p 值本身是连续的证据强弱。\(p=0.049\) 和 \(p=0.051\) 很接近;\(p=0.0001\) 和 \(p=0.049\) 都会拒绝 \(H_0\),但证据强度并不一样。
不要只写显著/不显著
报告里应给出具体 p 值,并同时报告效应大小和置信区间。只写“p<0.05”会丢掉很多信息。
7.4.4 八个常见误读¶
| 误读 | 为什么错 |
|---|---|
| p 是 \(H_0\) 为真的概率 | p 是 \(P(\text{数据}\mid H_0)\) |
| \(1-p\) 是 \(H_1\) 为真的概率 | p 不给 \(H_1\) 概率 |
| p 小代表效应大 | 大样本下很小效应也可能 p 小 |
| p 大代表没有效应 | 可能只是样本量太小、功效不足 |
| p=0.05 是科学真理 | 0.05 是历史惯例 |
| p 值能证明结果可重复 | 可重复性还受设计、样本、偏差影响 |
| 多试几次直到 p 小也可以 | 这是 p-hacking,会制造假阳性 |
| 只看 p 就能下结论 | 还要看效应大小、区间、研究设计 |
p-hacking 的直觉
如果反复换分组、换指标、换模型,直到某个 p 值小于 0.05,这个“显著”很可能只是筛出来的偶然波动。多重检验校正会在 §7.10 讨论。
7.4.5 Python 从 z 和 t 算 p 值¶
from scipy import stats
z = -1.92
print(f"z={z:.2f}, 左侧 p={stats.norm.cdf(z):.4f}")
print(f"z={z:.2f}, 双侧 p={2 * stats.norm.cdf(-abs(z)):.4f}")
t = -0.80
df = 15
print(f"t={t:.2f}, df={df}, 双侧 p={2 * stats.t.cdf(-abs(t), df):.4f}")
完整脚本见:
7.4.6 现代报告要三件套¶
一个更完整的写法是:
新方法平均提升 2.1 分,95% CI [0.4, 3.8],p=0.018。
这句话同时交代:
- 效应大小:提升 2.1 分。
- 不确定性:区间从 0.4 到 3.8。
- 证据强弱:p=0.018。
小率的笔记本
p 值是在 \(H_0\) 为真时,当前或更极端数据出现的概率。它不是 \(H_0\) 为真的概率,也不是效应大小。p 值要和 \(\alpha\) 比较做决策,但报告时应同时给具体 p 值、效应大小和置信区间。