7.11 分组测试实战¶
社团要办暑期义卖,小率做了两个报名页:A 版按钮写「立即报名」,B 版按钮写「帮我留名额」。他想把更好的版本发到全年级群里,但又担心前 20 个同学的反应只是碰巧。

两个页面谁更能让人报名
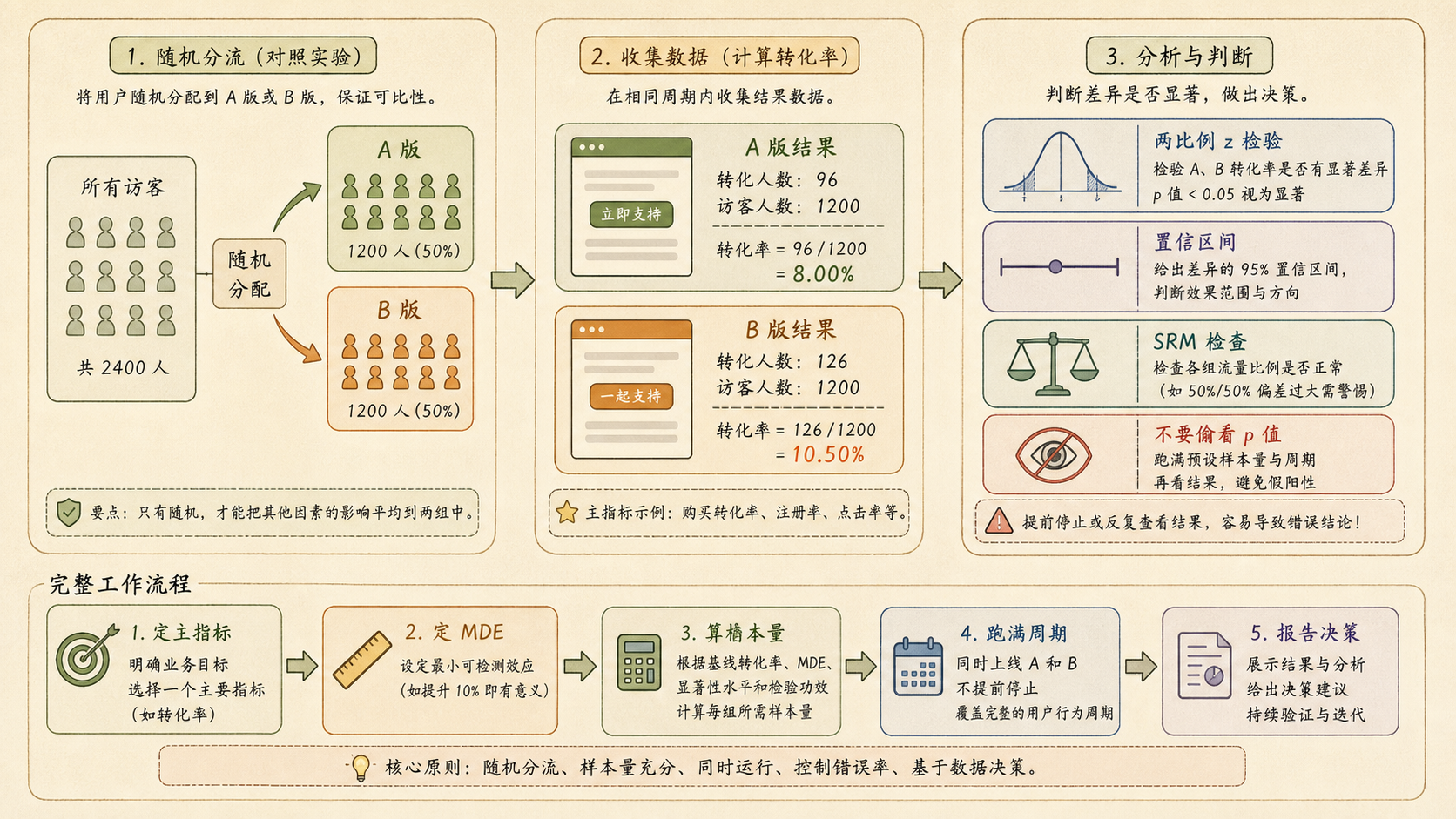
A/B 测试不是凭前几个人的直觉选版本,而是先随机分流,再按预定样本量收集数据,最后用比例检验或区间估计判断差异。
| 版本 | 访问人数 | 报名人数 | 转化率 |
|---|---|---|---|
| A 版 | 1 200 | 96 | 8.0% |
| B 版 | 1 200 | 126 | 10.5% |
7.11.1 A/B 测试的五步¶
正规的 A/B 测试至少包含五步:
- 确定主指标:例如报名转化率,不要跑完再挑最显著的指标。
- 确定 MDE:最小关心效应(Minimum Detectable Effect),例如提升 1 个百分点才值得改。
- 估算样本量:用 \(\alpha\) 和功效(Power)决定每组要多少人。
- 随机分流并跑满周期:不要一边看 p 值一边决定停。
- 报告效应、置信区间和 p 值:显著性和实际大小都要说清。
7.11.2 核心检验是两比例 z 检验¶
A/B 测试最常见的是比较两个比例:
合并比例为:
标准误为:
统计量为:
本例中 A 版 96/1200,B 版 126/1200。差异看起来是 2.5 个百分点,但还要用标准误判断它是否超出随机波动。
A/B 测试的三条高压线
第一,不要偷看 p 值提前停。第二,先检查分流比例是否异常,也就是 SRM。第三,多个指标一起看时要考虑多重检验校正。
7.11.3 样本量由 MDE 决定¶
如果基线转化率约 8%,你希望检出 1 个百分点的提升,也就是 8% 到 9%,那么每组样本量会远大于“随便收几百人”。效应越小,所需样本量增长越快。
实战建议
A/B 测试不是“先跑再说”,而是“先问多小的提升值得行动”。MDE 定不清,就无法判断需要多少样本,也无法判断何时停。
7.11.4 Python 跑一次完整 A/B¶
完整脚本见:docs/assets/scripts/ch07_hypothesis_testing/11_ab_testing/main.py。
import numpy as np
from scipy import stats
from statsmodels.stats.proportion import proportions_ztest, confint_proportions_2indep
success = np.array([96, 126])
nobs = np.array([1200, 1200])
z, p = proportions_ztest(success, nobs)
z_b_minus_a = -z
ci = confint_proportions_2indep(success[1], nobs[1], success[0], nobs[0], method="wald")
print(f"A 转化率 = {success[0] / nobs[0]:.3%}")
print(f"B 转化率 = {success[1] / nobs[1]:.3%}")
print(f"B-A 方向 z = {z_b_minus_a:.2f}, p = {p:.4f}")
print(f"B-A 的 95% CI = [{ci[0]:.3%}, {ci[1]:.3%}]")
srm_chi2, srm_p = stats.chisquare(nobs, f_exp=[1200, 1200])
print(f"SRM 检查 p = {srm_p:.3f}")
7.11.5 报告要能支持决策¶
一个合格的 A/B 报告不只写「p<0.05」:
社团报名页 A/B 报告
主指标:报名转化率。分流:A/B 各 1 200 人,SRM 检查通过。A 版 8.0%,B 版 10.5%,差异 +2.5 个百分点。比例 z 检验 p 值小于 0.05,95% 置信区间不跨 0。若没有副作用指标恶化,可以考虑上线 B 版。
小率的笔记本
A/B 测试 = 随机分流 + 预定样本量 + 比例或均值检验。先定主指标和 MDE,再跑实验;分析时同时看效应大小、置信区间、p 值、SRM 和多指标风险。