5.2 抽样方法¶
小率把班级社团问卷带来:全校 3000 名学生,想估计每周运动时间。直接在操场门口问人很方便,但均哥看了一眼就摇头:你在操场问到的人,当然更爱运动。

班级调查该怎么抽人
如果目标是全校学生,样本就不能只从操场、图书馆或某一个社团里来。抽样方法就是规定:谁有机会被抽中、机会是多少、怎样执行。
5.2.1 简单随机抽样:每个人机会相同¶
如果我把全校学号放进表格,然后随机抽 300 个,这算最公平吗?
这就是简单随机抽样。它直观、公平,但前提是你真的有完整名单。
简单随机抽样(Simple Random Sampling, SRS):总体中每个个体都有相同概率被抽中,且抽样规则不依赖个人特征。
适合:名单完整、调查成本差不多、总体内部差异不需要提前分组的场景。
5.2.2 分层抽样:先分组,再组内随机¶
全校运动时间可能被年级、性别、住宿情况影响。若只靠 SRS,某些小群体可能抽得太少。分层抽样(Stratified Sampling) 会先把总体分成互不重叠的层,再在每层随机抽样。
分层是不是像每个年级都派代表?
对。层内随机,层间都覆盖,尤其适合不同层差异很明显的时候。
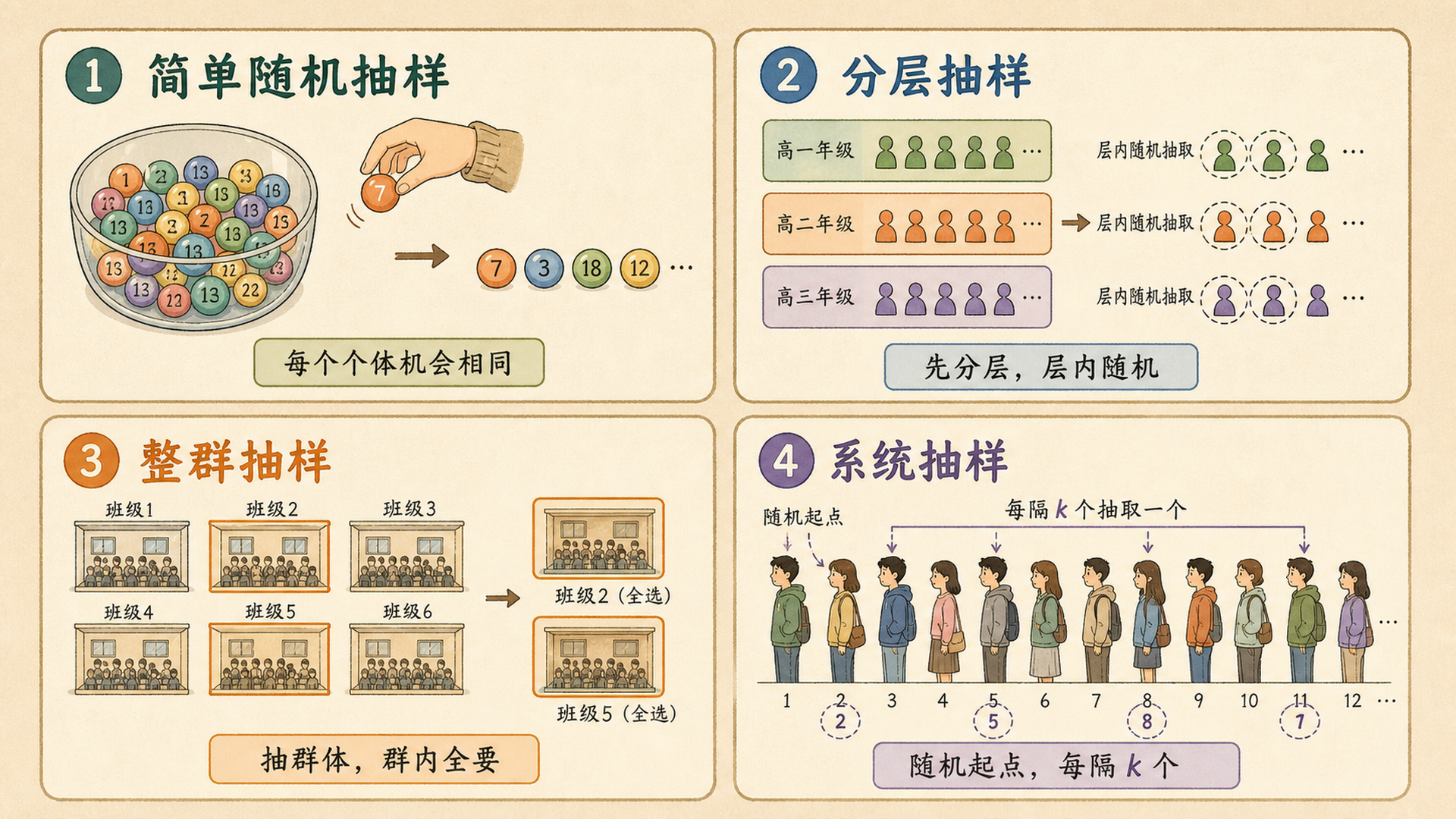
5.2.3 整群抽样:抽地点,不抽个体¶
整群抽样(Cluster Sampling) 先把总体分成很多天然群组,比如班级、小区、医院、门店;再随机抽几个群组,并调查群组内全部或部分个体。
它常常更便宜,但同一个群里的人往往更相似,所以精度可能下降。
整群抽样的代价
抽 10 个班、每班 30 人,名义样本量是 300。但同班同学作息相近,信息量可能小于从全校随机抽 300 人。这种损失叫设计效应(Design Effect)。
5.2.4 系统抽样:随机起点,每隔 k 个抽一个¶
系统抽样(Systematic Sampling) 先随机选一个起点,再按固定间隔抽样。例如名单排好后,从第 7 个开始,每隔 10 个抽 1 个。
听起来很省事,但如果名单排序有规律呢?
这正是风险。如果名单按宿舍、成绩或班级周期排列,固定间隔可能反复踩中同一类人。
5.2.5 四种方法怎么选¶
| 方法 | 适合情况 | 最大风险 |
|---|---|---|
| 简单随机抽样 | 有完整名单,个体访问成本相近 | 名单不完整 |
| 分层抽样 | 重要子群体必须覆盖 | 分层变量选错 |
| 整群抽样 | 地理或组织成本很高 | 群内太相似 |
| 系统抽样 | 名单已排序且无周期 | 排序周期造成偏差 |
选择口诀
有完整名单先想 SRS;子群差异大用分层;跑地点太贵用整群;名单很长且无周期可用系统抽样。
5.2.6 pandas 里实现一次分层抽样¶
import numpy as np
import pandas as pd
rng = np.random.default_rng(2026)
students = pd.DataFrame({
"student_id": np.arange(3000),
"grade": rng.choice(["高一", "高二", "高三"], size=3000, p=[0.34, 0.33, 0.33]),
"weekly_sport_hours": rng.gamma(shape=2.2, scale=1.6, size=3000)
})
# 每个年级按比例抽 10%
sample = (
students
.groupby("grade", group_keys=False)
.sample(frac=0.10, random_state=2026)
)
print(sample.groupby("grade").size())
print(f"样本平均运动时间:{sample['weekly_sport_hours'].mean():.2f} 小时/周")
这样每个年级都有人,不会只抽到高一吧?
对。分层抽样是在“代表性”上先做一道保险。
小率的笔记本
- SRS 最朴素,但需要完整名单。
- 分层抽样解决“重要子群体别漏掉”。
- 整群抽样省成本,但常牺牲精度。
- 系统抽样省事,但要检查名单周期。