4.3 连续型分布¶
公交站牌显示“预计 6 分钟到站”,可小率等了 4 分 20 秒。等待时间不像投篮命中次数那样数得清,它可以是 4.2 分钟、4.23 分钟、4.231 分钟……这时,概率不再堆在一个个点上,而是铺在一段连续的范围里。

恰好等 4.200000 分钟的概率是多少
对连续变量来说,单个点通常没有面积,所以单点概率往往是 0。真正有意义的是“等 3 到 5 分钟”这样的区间概率。
4.3.1 单点概率为什么是 0¶
我明明可能等 4.2 分钟,为什么说 $P(X=4.2)=0$?
不是说它不可能出现,而是说单个点没有宽度,面积为 0。
连续随机变量用概率密度函数(Probability Density Function, PDF)描述概率的“密度”。概率来自曲线下面积:
\[
P(a\le X\le b)=\int_a^b f(x)\,dx
\]
如果区间退化成一个点,宽度为 0,面积自然也是 0。
4.3.2 PDF 看高度,概率看面积¶
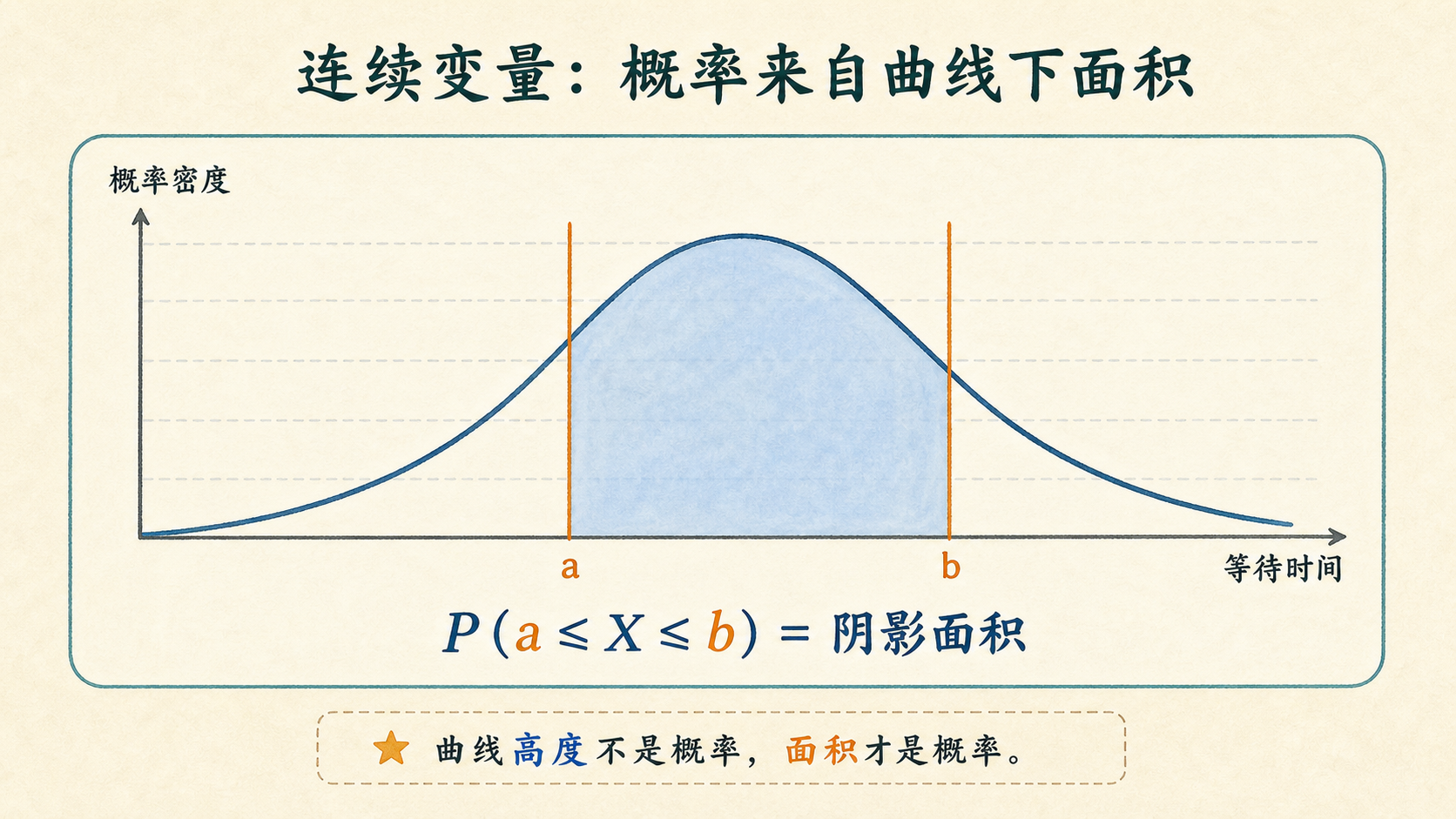
所以 PDF 可以大于 1?
可以。只要整条曲线下面积等于 1,局部高度超过 1 并不矛盾。
PDF 不是概率
\(f(2)=0.4\) 不能读成“\(X=2\) 的概率是 0.4”。它只能说明在 \(x=2\) 附近,概率密度的高度是 0.4。
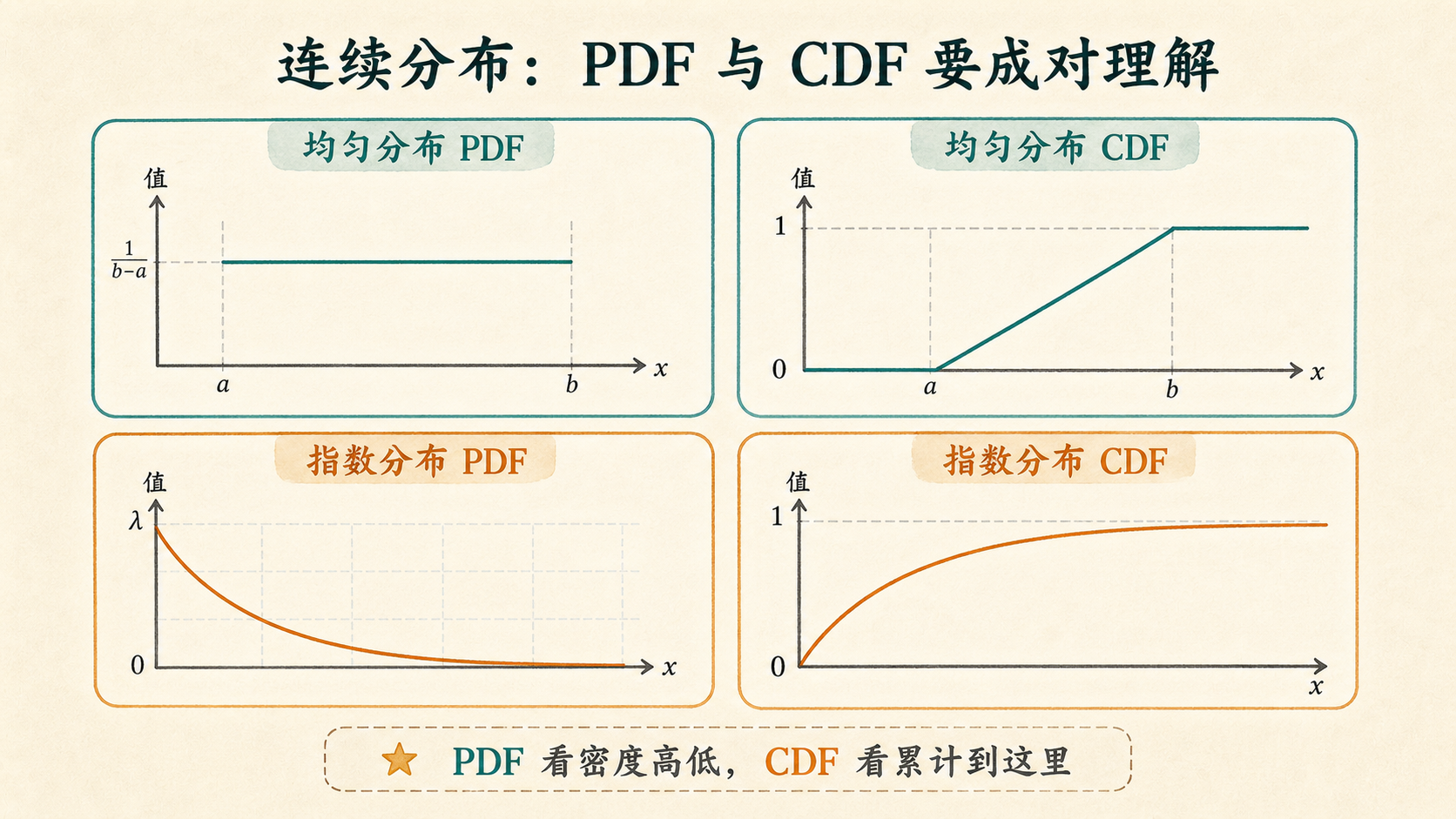
4.3.3 Uniform:每段同样公平¶
均匀分布(Uniform Distribution)适合描述“在一个区间里每个位置同样可能”的理想化情形。
若 \(X\sim U(a,b)\):
\[
f(x)=\frac{1}{b-a},\qquad a\le x\le b
\]
例如公交车在 0 到 10 分钟之间随机到达,如果没有其他信息,等候时间可以先用 \(U(0,10)\) 近似。
4.3.4 Exponential:等待下一次发生¶
指数分布(Exponential Distribution)常用于描述“等下一次事件发生”的时间。若平均每分钟发生率为 \(\lambda\):
\[
f(x)=\lambda e^{-\lambda x},\qquad x\ge 0
\]
4.3.5 指数分布的无记忆性¶
如果等待时间服从指数分布,那么已经等了多久,不会改变“从现在开始还要再等多久”的分布:
\[
P(X>s+t\mid X>s)=P(X>t)
\]
已经等了 10 分钟,竟然不代表马上就来?
对。无记忆性不是安慰剂,它只是一个特定模型的数学性质。
无记忆性不等于现实永远如此
真实公交受线路、红绿灯、调度影响,不一定满足指数分布。模型要服务现实,不能把假设当事实。
4.3.6 用 Python 算区间概率¶
from scipy import stats
# 等车时间先粗略看作 0 到 10 分钟均匀分布
wait = stats.uniform(loc=0, scale=10)
print(f"P(3 <= X <= 5) = {wait.cdf(5) - wait.cdf(3):.2f}")
# 平均 5 分钟来一次,指数分布的 lambda = 1/5
bus = stats.expon(scale=5)
print(f"P(X > 8) = {1 - bus.cdf(8):.2f}")
小率的笔记本
- 连续随机变量通常问区间概率,不问单点概率。
- PDF 的高度不是概率,曲线下面积才是概率。
- Uniform 适合“区间内同样可能”的理想场景。
- Exponential 常用来描述等待下一次事件发生的时间,但要检查假设是否合适。