11.2 因子分析¶
小率这次带来的是一张六科成绩表。数学、物理、化学经常一起高,语文、英语、历史也常常一起高。他想知道:这些可见分数背后,是不是有几种看不见的能力在起作用?

| 学生 | 数学 | 物理 | 化学 | 语文 | 英语 | 历史 |
|---|---|---|---|---|---|---|
| A | 91 | 88 | 86 | 71 | 74 | 70 |
| B | 68 | 70 | 72 | 89 | 92 | 85 |
| C | 84 | 80 | 83 | 82 | 79 | 81 |
| ... | ... | ... | ... | ... | ... | ... |
我不是只想压缩,我想知道“背后到底是什么能力”。
那就从 PCA 走到因子分析。PCA 重在压缩,因子分析重在解释。
11.2.1 相关变量背后的共同来源¶
因子分析(Factor Analysis)假设:多个观测变量之所以相关,是因为它们受到少数潜在因子的共同影响。
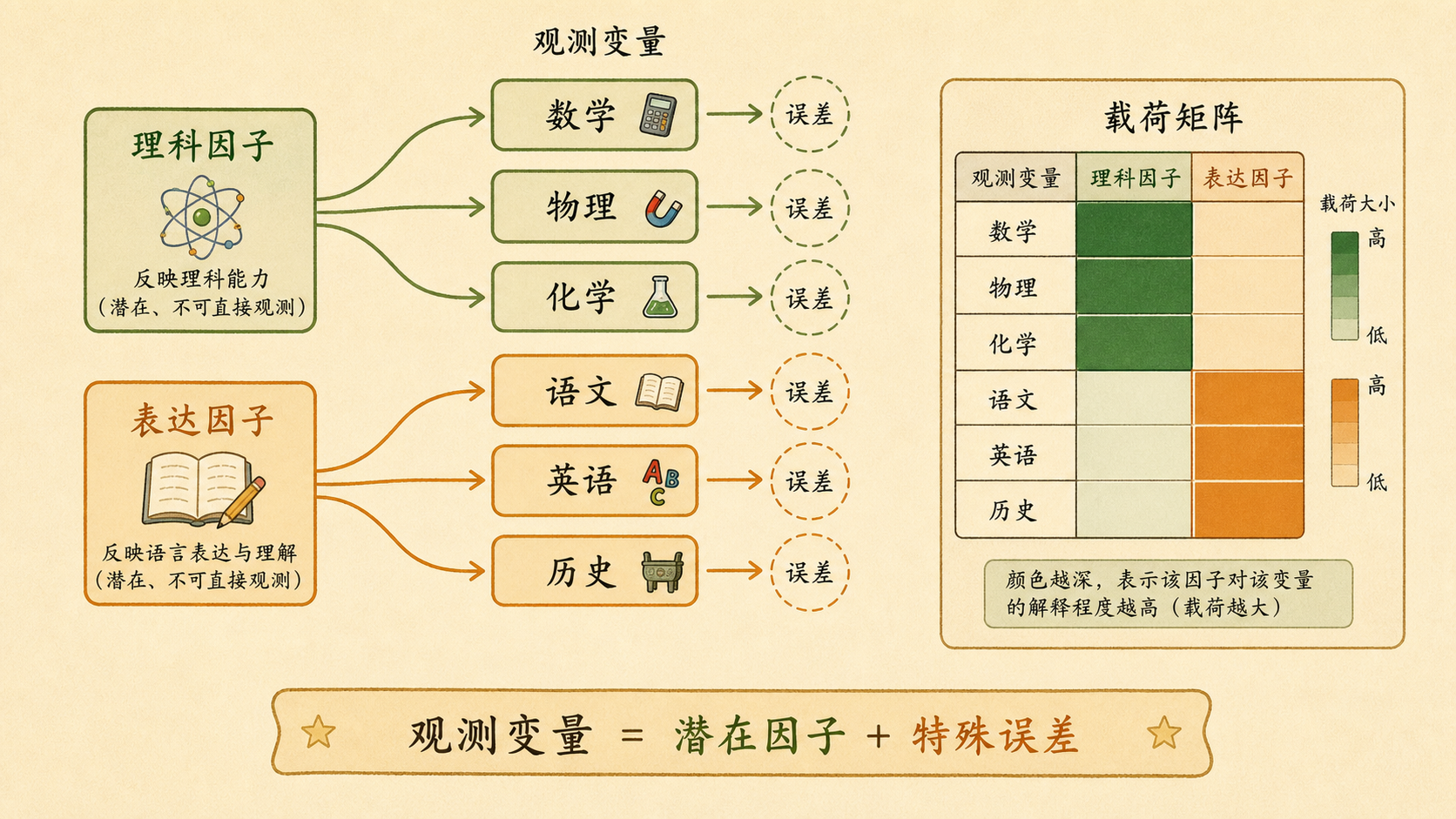
在六科成绩里,可以粗略想成:
- 数学、物理、化学被“理科因子”推动。
- 语文、英语、历史被“表达因子”推动。
- 每门课还保留自己的特殊误差,比如临场发挥、题型偏好。
11.2.2 因子模型怎么写¶
把每个学生的 \(p\) 个观测变量写成向量 \(X\),把 \(k\) 个看不见的因子写成 \(F\),因子模型是:
\[
X = L F + \varepsilon
\]
其中:
- \(L\) 是因子载荷矩阵,表示每个变量受每个因子影响的强度。
- \(F\) 是潜在因子。
- \(\varepsilon\) 是特殊因素或误差。
方差结构写成:
\[
\operatorname{Var}(X)=LL^\top+\Psi
\]
所以因子分析承认:有些方差是公共结构,有些只是每门课自己的波动。
对。这也是它和 PCA 最大的解释差异。
11.2.3 载荷、共同度和特殊度¶
载荷(Loading)越大,表示变量越受该因子影响。共同度(Communality)是一个变量被所有公共因子解释的方差比例:
\[
h_i^2=\sum_{j=1}^{k}l_{ij}^2
\]
特殊度则是没有被公共因子解释的部分:
\[
u_i^2=1-h_i^2
\]
三秒读载荷表
每一行看最大载荷在哪一列。数学、物理、化学如果都在同一列很高,这一列就可以命名为“理科因子”。
11.2.4 旋转让因子更好命名¶
因子分析常见问题是:初始载荷表不够清楚,许多变量在多个因子上都有中等载荷。旋转(Rotation)不会改变模型能解释多少总体结构,却能让载荷更接近“一个变量主要归一个因子”。
常见旋转:
| 旋转 | 关系 | 适合情况 |
|---|---|---|
| Varimax | 因子保持正交 | 默认选择,解释清楚 |
| Promax | 因子允许相关 | 潜在能力本来可能相关 |
| Oblimin | 因子允许相关 | 心理量表、问卷研究 |
旋转像是在把灯光调正,让影子更清楚?
这个比喻可以。它不创造新结构,只让结构更容易看见。
11.2.5 PCA 和因子分析别混用¶
| 问题 | PCA | 因子分析 |
|---|---|---|
| 主要目标 | 降维压缩 | 解释潜在结构 |
| 模型方向 | 主成分是变量组合 | 变量由因子生成 |
| 方差处理 | 解释总方差 | 解释公共方差 |
| 特殊误差 | 不单独建模 | 显式存在 |
| 典型输出 | 主成分坐标 | 因子载荷与因子得分 |
需要注意
如果报告里说“发现潜在心理维度”,通常应该使用因子分析而不是 PCA。PCA 可以帮助压缩,但不能自动证明潜在因子的存在。
11.2.6 用 Python 做因子分析¶
完整脚本放在:
import numpy as np
from sklearn.decomposition import FactorAnalysis
from sklearn.preprocessing import StandardScaler
rng = np.random.default_rng(42)
n = 300
science = rng.normal(size=n)
language = rng.normal(size=n)
X = np.column_stack([
0.85 * science + rng.normal(scale=0.35, size=n),
0.80 * science + rng.normal(scale=0.35, size=n),
0.78 * science + rng.normal(scale=0.35, size=n),
0.82 * language + rng.normal(scale=0.35, size=n),
0.86 * language + rng.normal(scale=0.35, size=n),
0.75 * language + rng.normal(scale=0.35, size=n),
])
X = StandardScaler().fit_transform(X)
fa = FactorAnalysis(n_components=2, rotation="varimax", random_state=0)
fa.fit(X)
loadings = fa.components_.T
print(loadings.round(2))
print("共同度:", (loadings ** 2).sum(axis=1).round(2))
11.2.7 什么时候用因子分析¶
适合:
- 心理量表、问卷题目背后的维度。
- 教育测量中的能力结构。
- 品牌调研中的潜在印象。
- 多个变量高度相关,且你关心“为什么相关”。
不适合:
- 只想快速压缩数据。
- 变量之间几乎不相关。
- 样本太少、变量太多。
- 因子命名缺少领域依据。
小率的笔记本
因子分析把观测变量写成“潜在因子 + 特殊误差”。载荷表告诉我们哪些变量受哪些因子影响,共同度告诉我们变量被公共因子解释了多少。PCA 更像压缩,因子分析更像解释结构。