16.1 医学临床试验分析¶
社区诊所里,小率陪家人做随访。柜台上有两盒彩色信封:一组患者会拿到新方案,另一组会拿到标准方案。均哥提醒他:“真正难的不是算一个平均值,而是让两组人尽量可比,再判断差异是不是来自治疗。”
随机对照试验(Randomized Controlled Trial, RCT)就是医学研究里最重要的设计之一。它用随机分组减少偏差,用统计推断衡量疗效的不确定性。
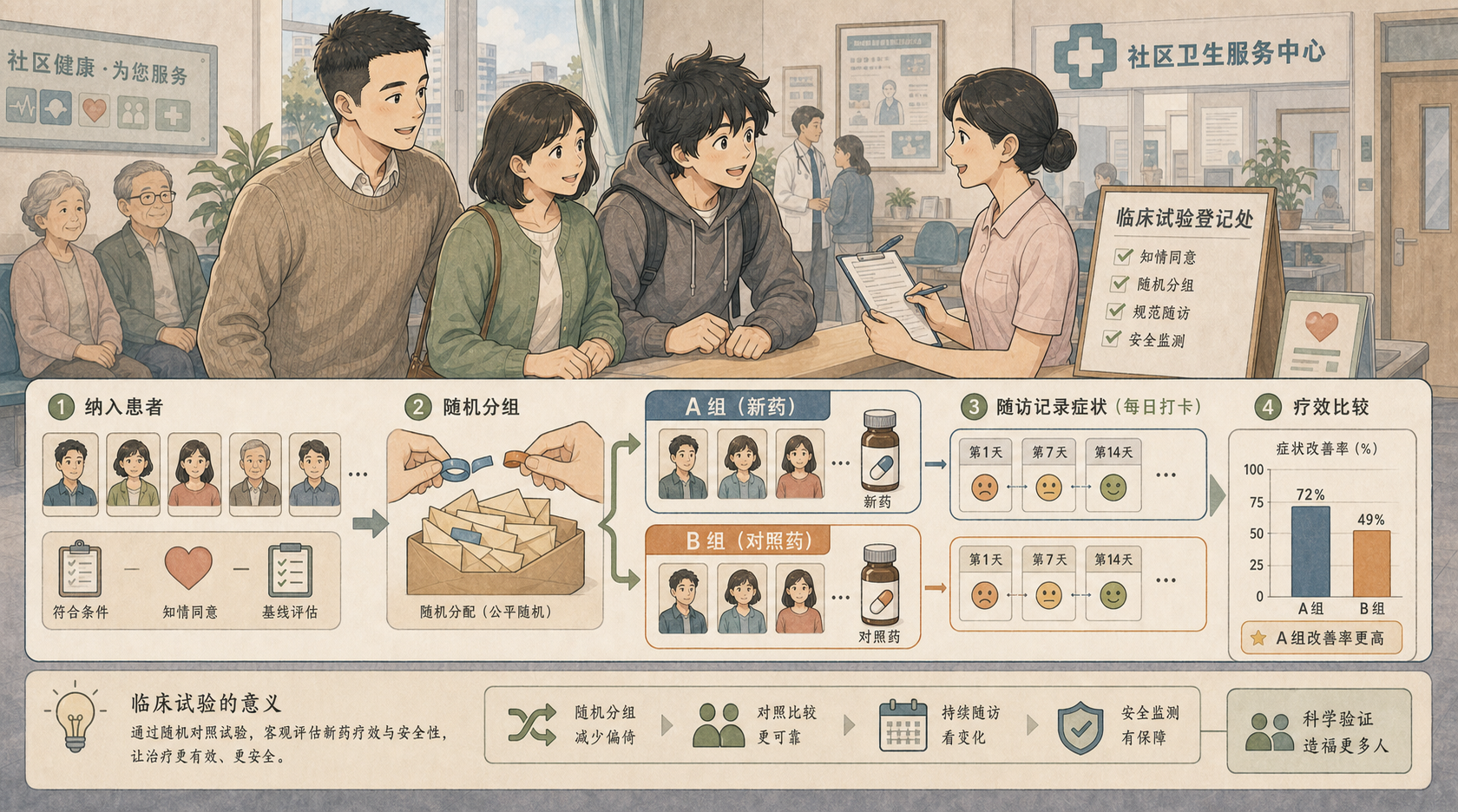
16.1.1 先把疗效问题改写成可比较的两组¶
临床试验的核心问题通常是:
新治疗是否比对照治疗更有效、更安全?
最基本的比较可以写成:
其中 \(Y\) 可以是血压下降值、症状评分改善值、复发率或生存时间。随机分组的作用,是让年龄、基础病、生活习惯等因素在两组中尽量平衡。
| 患者 | 分组 | 治疗前评分 | 治疗后评分 | 改善值 |
|---|---|---|---|---|
| A | 新方案 | 8 | 4 | 4 |
| B | 对照 | 7 | 5 | 2 |
| C | 新方案 | 6 | 3 | 3 |
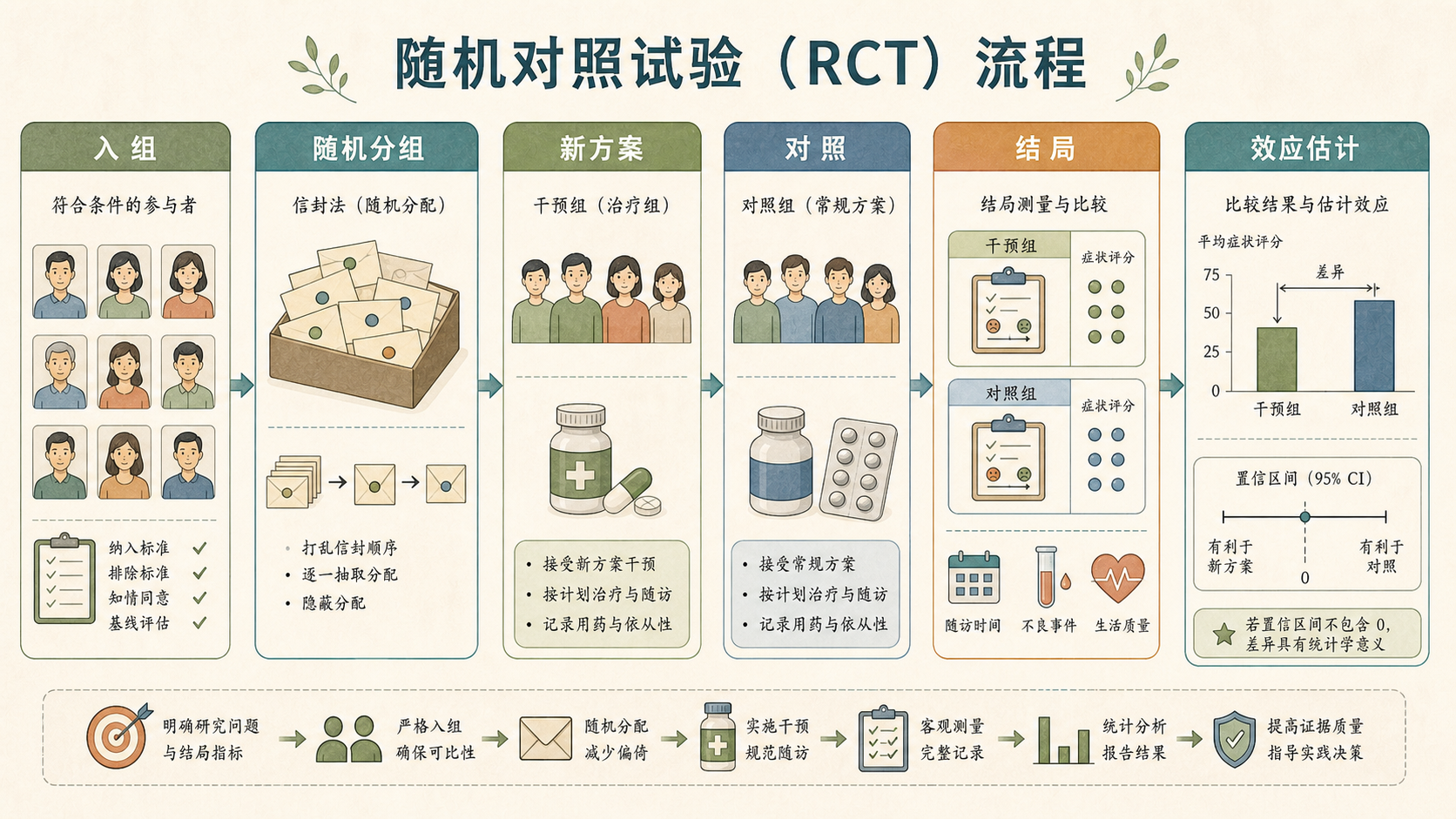
16.1.2 随机化之前先定义终点¶
临床试验最怕“做完以后再挑好看的结果”。所以在正式开始前,研究方案里要写清楚:
- 主要终点:最核心的疗效指标,例如 12 周后的症状评分改善。
- 次要终点:辅助指标,例如复发率、生活质量评分、不良反应。
- 分析人群:按意向治疗(Intention-to-Treat, ITT)还是按实际完成治疗者分析。
- 样本量:预期效应多大、允许多大误差、希望检验有多大把握。
样本量不是越大越好,而是在伦理、成本和统计功效之间平衡。太小看不出真实疗效,太大可能把微小但无临床意义的差异也做成“显著”。
16.1.3 差异要同时看大小和不确定性¶
如果结局是连续变量,可以用两组均值差的置信区间:
如果结局是“是否康复”,常比较风险差、相对风险或优势比。若关注“多久后复发/死亡/流失”,就进入生存分析,本章 16.4 会展开。
临床显著不等于统计显著
p 值小只说明在零效应假设下观察到这种差异不太常见;它不自动说明疗效足够大、足够安全、足够值得推广。
16.1.4 脱落和缺失会改变结论¶
临床试验中,患者可能中途退出、忘记随访、换药或发生不良反应。处理这些情况时,要区分两种分析思路:
| 分析方式 | 怎么做 | 优点 | 风险 |
|---|---|---|---|
| ITT | 按最初随机分组分析 | 保留随机化优势,更接近真实推广 | 治疗依从性差时效应被稀释 |
| Per-protocol | 只分析按方案完成者 | 更接近“按要求治疗”的效果 | 可能破坏随机化,产生选择偏差 |
均哥的小提醒
试验报告里不要只找“显著”的子组。子组越多,偶然显著的机会越大。若子组分析不是事先计划好的,应当标注为探索性结果。
16.1.5 用模拟数据做一次两组检验¶
import numpy as np
from scipy import stats
rng = np.random.default_rng(42)
new_plan = rng.normal(loc=4.2, scale=1.4, size=60)
standard = rng.normal(loc=3.3, scale=1.5, size=60)
t_stat, p_value = stats.ttest_ind(new_plan, standard, equal_var=False)
diff = new_plan.mean() - standard.mean()
print("mean difference:", round(diff, 3))
print("t:", round(t_stat, 3))
print("p:", round(p_value, 4))
这段代码只演示推断逻辑。真实临床试验还要事先注册方案、定义主要终点、处理缺失与脱落、监测不良反应,并遵守伦理审查。
16.1.6 把结果写成人能读懂的话¶
一份合格的试验摘要,不应该只写“p=0.03”。更好的写法是:
新方案组平均改善 4.2 分,对照组平均改善 3.3 分,均值差为 0.9 分。95% 置信区间为 0.2 到 1.6 分,提示新方案可能带来额外改善;但仍需结合不良反应、费用和患者可接受性判断是否推广。
这句话同时交代了效应方向、效应大小、不确定性和决策边界。
小率的笔记本
医学试验先靠设计减少偏差,再靠统计量化不确定性。结论不能只看 p 值,还要看效应大小、置信区间、安全性、样本代表性和临床意义。