2.2 变量与数据类型¶
班主任让小率整理一份班级社团报名和通勤问卷。小率发现每一列都“不太一样”:有的是数字,有的是选项,有的是等级,有的是是否参加。
均哥看了一眼,说这不是表格排版问题,而是统计分析前的第一道门:先判断每一列是什么类型。
如果把数据表想成一个装满物品的抽屉,变量类型就是先把物品分成“衣服、书、工具、票据”。分错了类,后面就会拿错工具。给社团名称算平均值、把满意度等级当成精确距离、把学生编号当成普通数字,都是因为变量类型没想清楚。

2.2.1 变量是我们真正记录的东西¶
先看这张问卷表
| 学生 | 年级 | 通勤时间 | 社团兴趣 | 是否参加校队 |
|---|---|---|---|---|
| A | 7 | 18 分钟 | 篮球 | 是 |
| B | 8 | 31 分钟 | 绘画 | 否 |
| C | 7 | 12 分钟 | 篮球 | 否 |
| ... | ... | ... | ... | ... |
变量(Variable) 是每个观察对象身上被记录的特征。学生是观察对象;年级、通勤时间、社团兴趣、是否参加校队,都是变量。
就拿这张问卷表来说:
- **每一行**是一位填写问卷的学生,比如 A、B、C。
- **每一列**是这位学生身上的一个特征,比如年级、通勤时间、社团兴趣。
- **每个单元格**是一位学生在某个变量上的答案,比如 A 同学通勤 18 分钟、社团兴趣是篮球。
这个读法很朴素,却非常重要。很多初学者一看到表格就急着调用软件函数,但软件只知道这一列是文字还是数字,不知道“篮球”是社团兴趣,“18 分钟”是通勤时间,“是/否”是是否参加校队。统计分析必须由人先判断含义。
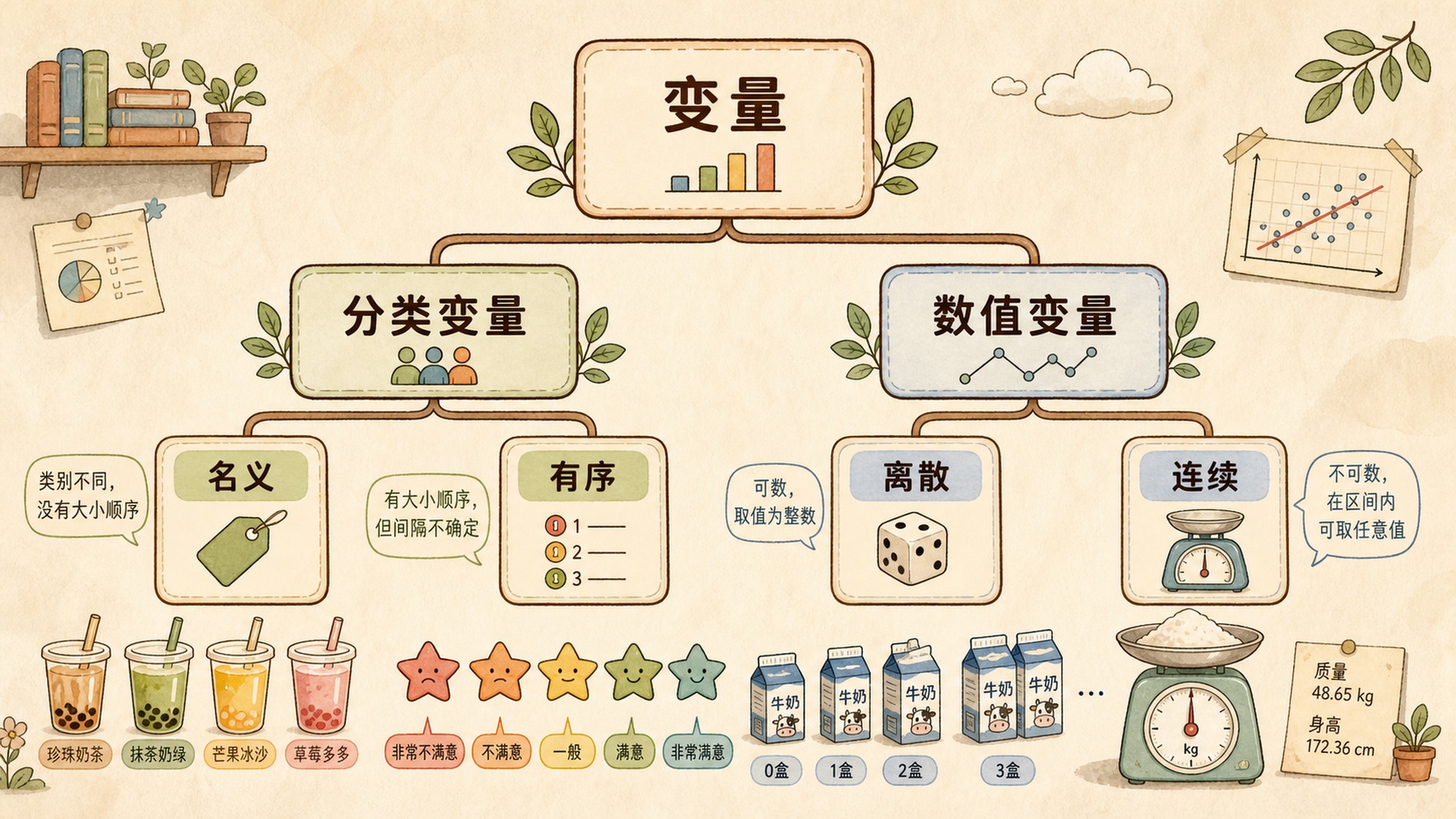
2.2.2 分类变量:名字和标签¶
分类变量(Categorical Variable) 的取值表示类别,而不是可以随意加减乘除的数量。
常见分类变量有两类:
| 类型 | 含义 | 例子 | 适合怎么描述 |
|---|---|---|---|
| 名义变量 Nominal | 类别之间没有天然顺序 | 社团兴趣、是否参加校队 | 频数、比例、条形图 |
| 有序变量 Ordinal | 类别有顺序,但间距不一定相等 | 对通勤体验的满意度等级 | 频数、比例、中位等级 |
需要注意
数字编码不等于数值变量。比如“1=男、2=女”只是标签编码,不能说 2 比 1 大,也不能计算平均性别。
还有一种常见陷阱是编号。问卷表里如果有“学生编号”,它看起来是数字,但主要用来识别学生,不是用来做大小比较。编号 20260416 并不比 20260415 “大一点学习成绩”,它只是排在后面的一个标签。
2.2.3 数值变量:可以计算的数量¶
数值变量(Numerical Variable) 的取值代表数量,可以进行有意义的加减比较。
数值变量也常分成两类:
| 类型 | 含义 | 例子 |
|---|---|---|
| 离散变量 Discrete | 通过计数得到,通常是整数 | 本周缺勤次数、参加社团数量 |
| 连续变量 Continuous | 通过测量得到,可以有小数 | 通勤时间、到校用时 |
数值变量还有一个隐藏但很重要的细节:单位。通勤时间是分钟还是小时,本周缺勤是次数还是天数,都会影响计算和图表。单位没写清楚,数字就像没有标尺的地图。
| 变量 | 单位写清楚前 | 单位写清楚后 |
|---|---|---|
| 通勤时间 | 18 | 18 分钟 |
| 到校用时 | 0.5 | 0.5 小时 |
| 本周缺勤 | 2 | 2 次 |
| 参加社团数量 | 1 | 1 个 |
变量名要带上单位
数据表列名最好写成“通勤时间_分钟”“到校用时_小时”“本周缺勤_次”。这会让后续画图、建模和复查都少很多误会。
2.2.4 Likert 量表为什么容易让人纠结¶
班级问卷里如果继续追问“你对通勤体验满意吗”,常见写法是 Likert 量表,比如:
| 选项 | 编码 |
|---|---|
| 非常不同意 | 1 |
| 不同意 | 2 |
| 一般 | 3 |
| 同意 | 4 |
| 非常同意 | 5 |
它看起来像数字,但本质上是有序等级。是否能计算平均分,要看研究场景和假设是否合理。
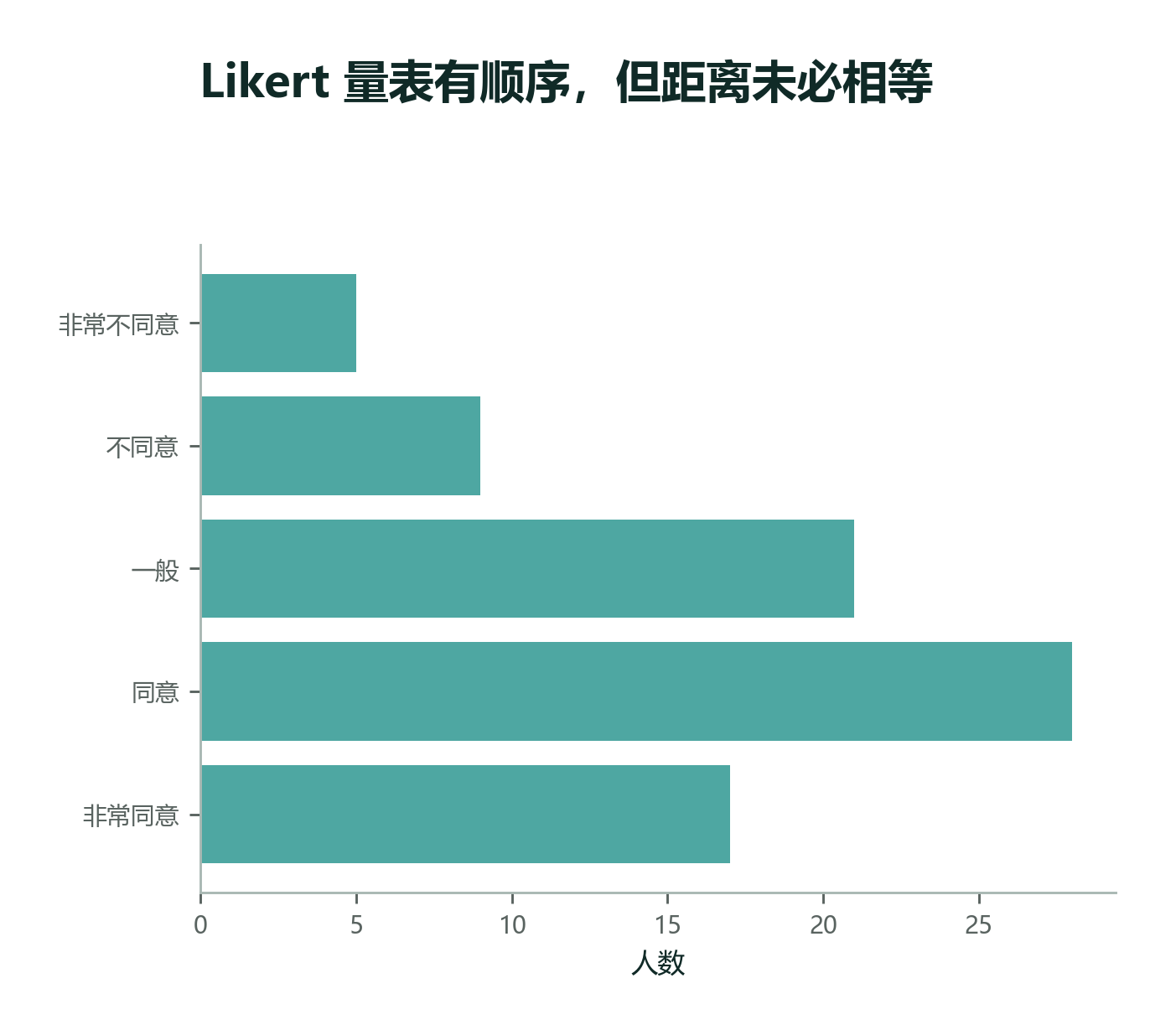
实用判断
单个 Likert 题目优先当有序变量处理;多个题目合成稳定量表后,很多应用会近似当数值变量分析,但报告时要说明处理方式。
这里的关键不是“绝对能不能算平均”,而是“你愿意不愿意承认一个假设”:从 1 到 2、从 2 到 3、从 3 到 4 的心理距离差不多。如果只是一个题目,这个假设往往太强;如果是多个题目组成的量表,随机波动会被平均掉一些,实践中就更常见地把总分或平均分当作近似数值变量。
2.2.5 缺失值也是一种信息¶
问卷里经常会出现空白:有人没填通勤时间,有人跳过了社团兴趣,有人把“是否参加校队”留空。初学者很容易把这些空白当成麻烦,直接删掉。
但缺失值(Missing Value)本身也可能有含义。
| 缺失情况 | 可能原因 | 处理前要问 |
|---|---|---|
| 通勤时间没填 | 忘记填、住校、不愿透露 | 缺失是否集中在某一类学生 |
| 社团兴趣没填 | 还没想好、没有想参加的社团 | 是否应该增加“暂未决定”选项 |
| 是否参加校队没填 | 不确定资格、漏填 | 是否集中在某个年级或某个班 |
如果缺失是随机的,影响可能较小;如果缺失集中在某一类人身上,直接删除就可能造成偏差。比如住校生没有填写通勤时间,并不代表他们“通勤时间为 0”;如果把这些空白直接删掉,最后得到的通勤结论就只适合走读生,不能代表全班。
不要把空白一删了之
处理缺失值前,先统计每一列缺了多少,再看缺失是否集中在某些群体。缺失不是脏东西,它可能正在告诉你调查方式出了问题。
2.2.6 用 Python 看列类型¶
import pandas as pd
df = pd.DataFrame({
"年级": [7, 8, 7],
"通勤时间": [18, 31, 12],
"社团兴趣": ["篮球", "绘画", "篮球"],
"是否参加校队": ["是", "否", "否"],
})
print(df.dtypes)
print(df["社团兴趣"].value_counts())
print(df["通勤时间"].mean())
print(df.isna().sum())
这段代码提醒我们:Python 的 object、category、int64 只是计算机看到的数据类型;统计分析还要由人判断变量含义。
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/02_variable_and_data.py,可以复现变量类型判断和简单汇总。
小率的笔记本
- 变量是观察对象身上被记录的特征。
- 分类变量描述类别,数值变量描述数量。
- 名义变量没有顺序,有序变量有顺序但间距未必相等。
- 离散变量来自计数,连续变量来自测量。
- 数字编码不等于数值变量,先理解含义再选择统计方法。
- 单位和缺失值也属于数据含义的一部分,不能交给软件自动猜。