7.10 多重检验校正¶
小率把社团活动后台导出的 30 张小卡片铺开:海报颜色、按钮文案、报名入口、推送时间……每张卡片都有一个 p 值。有 2 张卡片低于 0.05,他兴奋地说「这两个改动有效」。

7.10.1 检验越多,越容易捡到假阳性¶
单次检验把第一类错误率控制在 \(\alpha=0.05\),意思是:如果原假设真的成立,仍有 5% 的机会误拒绝它。
如果同时做 \(m\) 次独立检验,并且所有原假设都是真的,那么至少出现一次假阳性的概率是:
当 \(\alpha=0.05\)、\(m=30\):
也就是说,至少捡到一个假阳性的概率接近 79%。
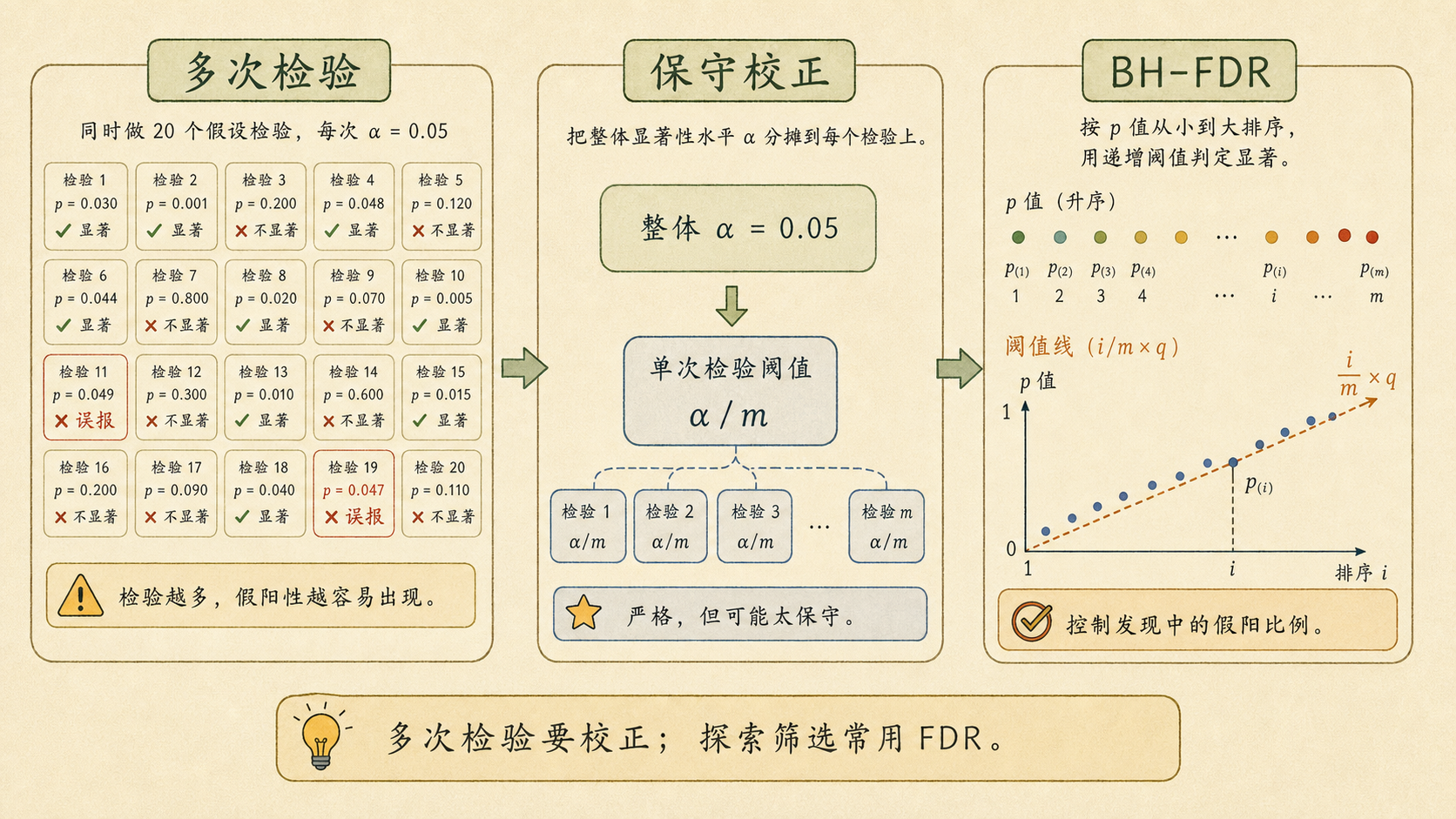
7.10.2 Bonferroni:把 α 分给每一次检验¶
Bonferroni 校正很直接:如果总错误率要控制在 \(\alpha\),做 \(m\) 次检验时,每次只允许:
30 次检验时,阈值就是:
只有 p 值小于 0.0017 才算通过。它非常稳,但也非常保守。
7.10.3 BH-FDR:允许发现里有少量假阳性¶
错误发现率(False Discovery Rate, FDR)控制的是:
Benjamini-Hochberg(BH)方法的做法是:
- 把 p 值从小到大排序:\(p_{(1)} \leq p_{(2)} \leq \cdots \leq p_{(m)}\);
- 找最大的 \(i\),使得:
- 拒绝前 \(i\) 个原假设。
其中 \(q\) 是想控制的 FDR,比如 0.05 或 0.10。
什么时候用哪一个
临床主终点、质量安全这类高风险问题,优先控制 FWER,可用 Holm 或 Bonferroni。探索性筛选、海量特征、基因或大量 A/B 指标,通常用 BH-FDR,再用独立数据复验。
7.10.4 Python 比较校正前后¶
完整脚本见:docs/assets/scripts/ch07_hypothesis_testing/10_multiple_testing/main.py。
import numpy as np
p_values = np.array([0.001, 0.008, 0.012, 0.04, 0.049, 0.08, 0.20, 0.31])
alpha = 0.05
m = len(p_values)
bonferroni = p_values <= alpha / m
order = np.argsort(p_values)
ranked = p_values[order]
thresholds = alpha * (np.arange(1, m + 1) / m)
passed = ranked <= thresholds
k = np.where(passed)[0].max() + 1 if passed.any() else 0
bh = np.zeros(m, dtype=bool)
bh[order[:k]] = True
print("原始 p<0.05:", p_values[p_values < alpha])
print("Bonferroni 通过:", p_values[bonferroni])
print("BH-FDR 通过:", p_values[bh])
需要注意
多重检验校正不能替代研究设计。反复试很多分组、很多模型、很多指标,再只报告显著结果,是 p-hacking。校正、预注册、完整报告检验次数,要一起用。
小率的笔记本
做一次检验时,\(\alpha=0.05\) 是单次错误率;做很多次时,要控制整体风险。Bonferroni 问“至少一个假阳性能不能少”,BH-FDR 问“发现结果里假阳比例能不能受控”。