16.3 文本分析与自然语言处理¶
咖啡店的意见箱被倒在桌上:有人写“拿铁很香”,有人写“排队太久”,也有人抱怨“外卖包装漏了”。小率想一张张读,均哥则把卡片按主题和情绪分成几堆。
自然语言处理(Natural Language Processing, NLP)就是把文字变成可分析的数据:先表示文本,再做分类、聚类、检索或生成。

16.3.1 文字先要变成向量¶
最传统的方式是词袋模型(Bag of Words):只记录词出现了几次,不关心顺序。
若词表是:
\[
[\text{好喝}, \text{排队}, \text{外卖}, \text{贵}]
\]
评论“咖啡好喝,但排队太久”可以表示成:
\[
[1,1,0,0]
\]
TF-IDF 会进一步降低常见词的权重,提高能区分文本的词:
\[
\text{tfidf}(t,d)=\text{tf}(t,d)\times \log\frac{N}{df(t)}
\]
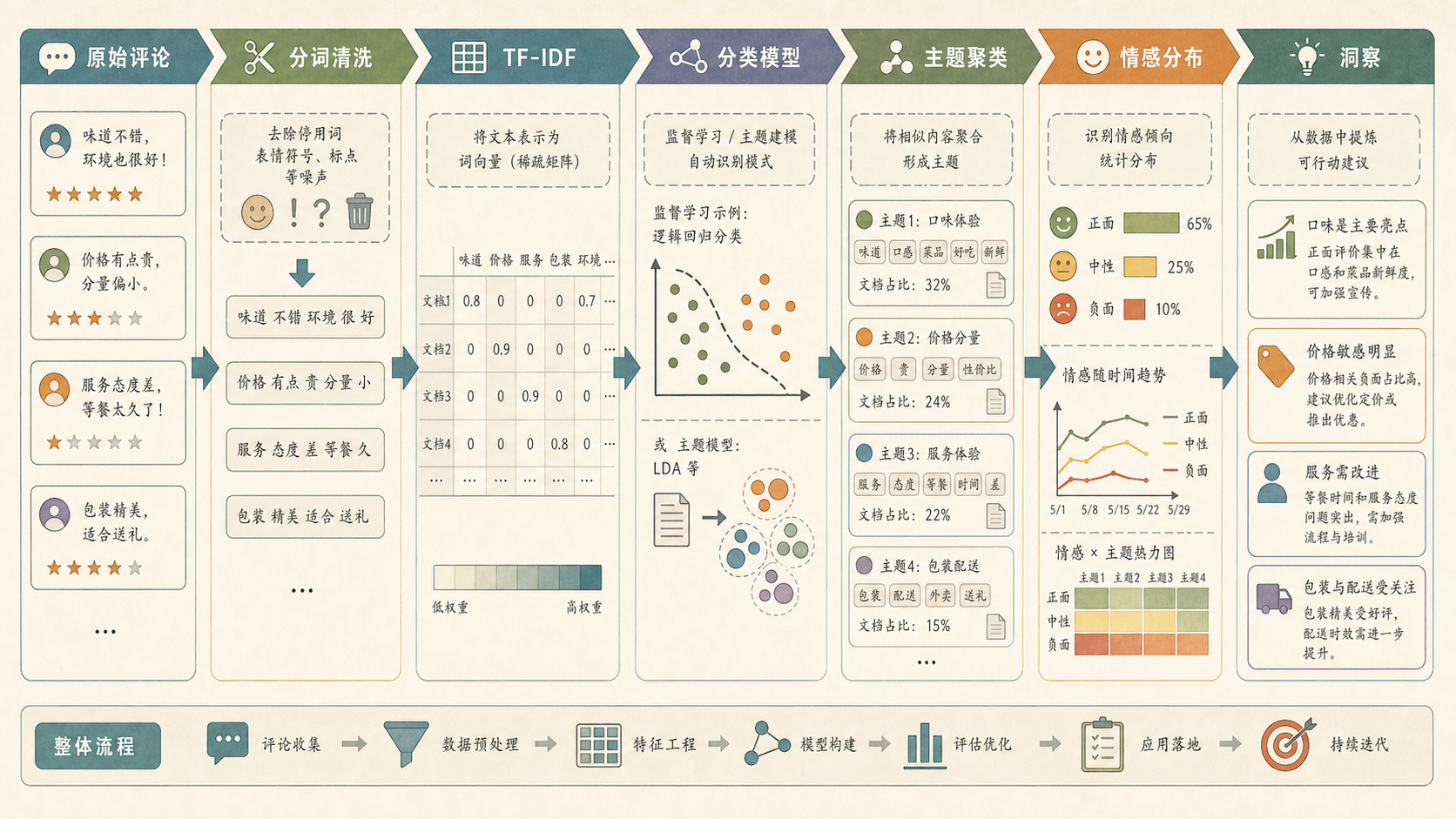
16.3.2 情感分析是一个分类问题¶
如果目标是判断评论正面、负面或中性,可以把它当作监督学习:
| 评论 | 标签 |
|---|---|
| 咖啡好喝,环境舒服 | 正面 |
| 等餐太久,体验一般 | 负面 |
| 价格正常,位置方便 | 中性 |
现代 NLP 还会使用词向量、Transformer 表示和大语言模型。但在许多真实项目中,TF-IDF + 逻辑回归仍然是很强的基线。
16.3.3 主题提取帮我们看见高频问题¶
情感标签只能告诉我们“好不好”,主题模型或聚类能进一步告诉我们“为什么好/坏”。例如咖啡店评论可能分成:
| 主题 | 高频词 | 可行动解释 |
|---|---|---|
| 口味 | 好喝、香、甜、拿铁 | 产品本身反馈 |
| 价格 | 贵、优惠、学生、套餐 | 定价与促销 |
| 服务 | 排队、态度、出餐、外卖 | 运营流程 |
| 环境 | 安静、座位、灯光、插座 | 空间体验 |
主题不是模型自动给出的真理。模型只给词和文本分组,真正的主题命名需要人回到原文检查。
16.3.4 先跑一个轻量情感分类基线¶
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
texts = [
"咖啡 好喝 环境 舒服",
"服务 热情 味道 很好",
"排队 太久 体验 一般",
"外卖 包装 漏了 很差",
]
labels = [1, 1, 0, 0]
clf = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
clf.fit(texts, labels)
print(clf.predict(["咖啡 味道 好 服务 舒服"]))
16.3.5 评价文本模型不能只看准确率¶
如果负面评论只占 10%,模型永远预测“正面”也能有 90% 准确率。此时更应该看:
- Precision:判为负面的评论里,有多少真是负面。
- Recall:真实负面评论里,有多少被找出来。
- F1:Precision 和 Recall 的折中。
- 混淆矩阵:哪些类别最容易被混淆。
文本模型会继承语料偏差
如果训练评论来自少数用户、某个平台或某段时间,模型学到的可能是平台偏见、热点词或噪声,而不是真正稳定的语言规律。
小率的笔记本
文本分析的第一步是表示:词袋、TF-IDF、词向量、Transformer 都是在回答“怎样把文字变成数字”。做项目时先跑简单基线,再决定是否需要大模型。