10.6 贝叶斯派与频率派¶
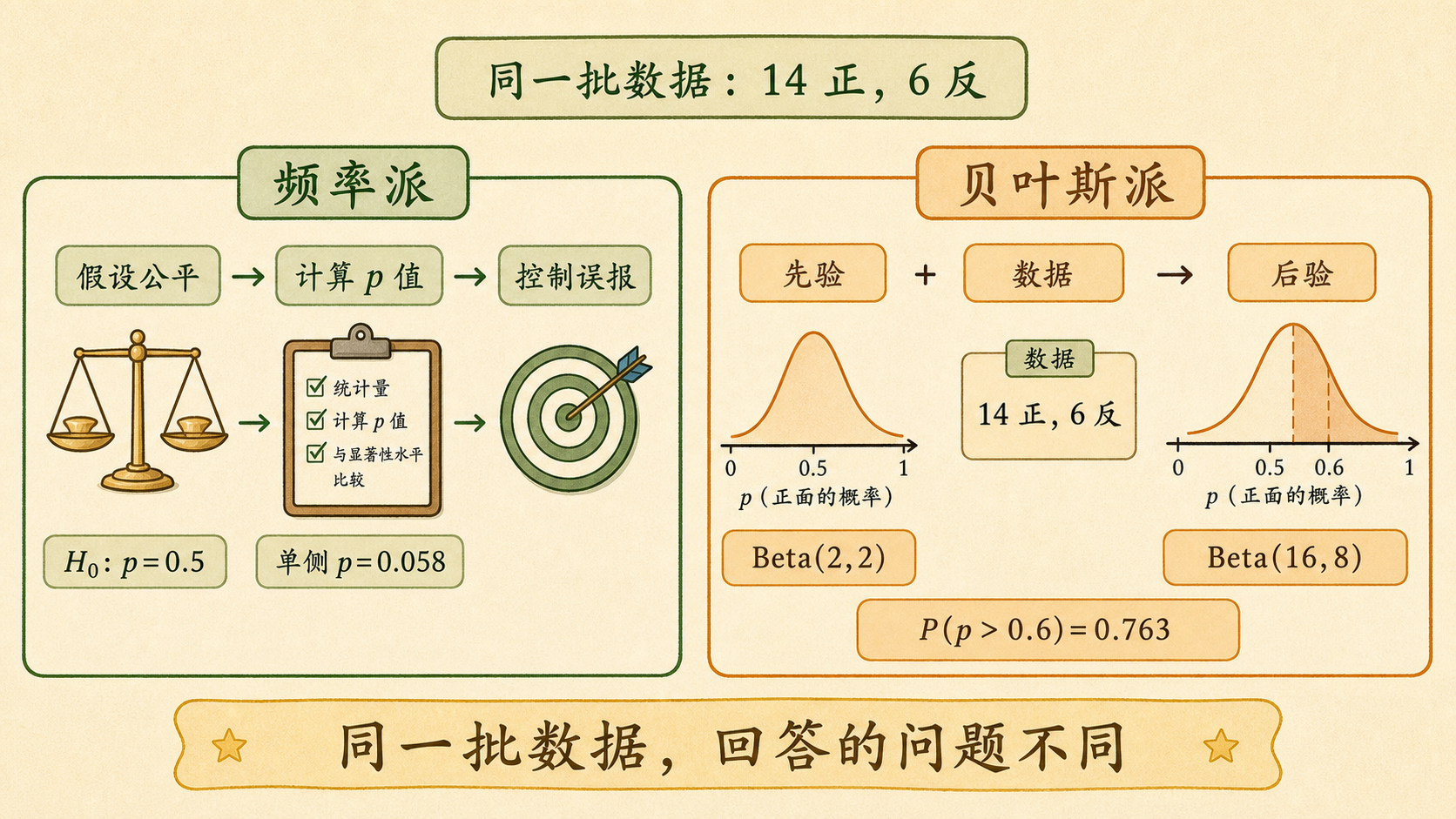
暑假下午,小率把那枚练习用硬币和一页记录纸摊在奶茶店桌上。这一次,他抛了 20 次,结果是 14 次正面、6 次反面。看起来有点偏,但偏到足以怀疑它不公平吗?

| 抛掷次数 | 正面 | 反面 | 样本正面比例 |
|---|---|---|---|
| 20 | 14 | 6 | 0.70 |
同一组数据,频率派和贝叶斯派会给同一个答案吗?
它们常常方向接近,但说话方式不同。一个问“长期误报率怎么控制”,一个问“看完数据后我该相信什么”。
10.6.1 同一枚硬币,两种问题¶
频率派会先假设硬币公平:
\[
H_0:p=0.5
\]
然后问:如果硬币真的公平,20 次里看到 14 次或更多正面,这类结果有多罕见?
贝叶斯派会先给正面概率 \(p\) 一个先验,比如:
\[
p\sim \text{Beta}(2,2)
\]
看完 14 正 6 反后,得到后验:
\[
p\mid D\sim \text{Beta}(16,8)
\]
然后可以直接问:
\[
P(p>0.6\mid D)
\]
也就是说,频率派问“如果公平,数据有多极端”;贝叶斯问“看到数据后,偏向正面的可信度有多高”。
10.6.2 参数到底是常数还是变量¶
两派最根本的分歧是:未知参数 \(\theta\) 到底该怎么理解?
| 问题 | 频率派 | 贝叶斯派 |
|---|---|---|
| 参数 | 未知但固定的常数 | 用随机变量表达信念 |
| 概率 | 长期重复频率 | 对未知的信念程度 |
| 数据 | 重复抽样中会变化 | 已经观察到的证据 |
| 推断目标 | 控制长期错误率 | 更新当前不确定性 |
一句话
频率派把参数当固定真值,贝叶斯派把我们对参数的认识写成分布。
10.6.3 区间的解释完全不同¶
频率派的 95% 置信区间(Confidence Interval)不能解释成“参数有 95% 概率在区间里”。在频率派世界里,参数是固定的,随机的是区间构造过程。
贝叶斯的 95% 信用区间(Credible Interval)可以直接解释成:在当前模型、先验和数据下,参数有 95% 的后验概率落在这个区间里。
所以很多人平时对置信区间的直觉,其实更像贝叶斯信用区间?
对。人脑很自然地想说“参数在这里的概率”,但频率派区间不是这个语义。
10.6.4 检验也在回答不同问题¶
| 任务 | 频率派说法 | 贝叶斯说法 |
|---|---|---|
| 硬币是否公平 | p 值是否足够小 | 公平模型和偏硬币模型哪个更可信 |
| A/B 测试 | 若无差异,看到这类数据有多罕见 | B 优于 A 的后验概率是多少 |
| 区间估计 | 重复抽样时区间覆盖真值的比例 | 参数落在区间里的后验概率 |
| 预测 | 插入估计值再给预测区间 | 积分掉参数不确定性得到后验预测 |
频率派 p 值不是“原假设为真的概率”。贝叶斯后验概率也不是天然客观真理,它依赖先验、模型和数据质量。两者都要小心解释。
别把语言互相硬套
不要把 p 值解释成“假设为真的概率”,也不要把贝叶斯后验概率解释成脱离先验和模型的绝对事实。
10.6.5 什么时候用哪一种¶
更倾向频率派的情况:
- 数据量很大,先验影响很小。
- 需要标准化、可审计的长期错误率控制。
- 监管、论文或平台规范要求 p 值、置信区间、固定停止规则。
- 目标是快速估计或高吞吐建模。
更倾向贝叶斯的情况:
- 样本少,但有可靠历史经验。
- 需要直接表达“某方案更好概率”。
- 需要连续更新判断。
- 有层次结构,希望部分池化。
- 决策要显式考虑损失和不确定性。
实战建议
不必把两派当成信仰。简单大样本问题用频率派通常更经济;小样本、决策导向、层次结构和连续更新问题,贝叶斯往往更自然。
10.6.6 用 Python 对照两种回答¶
配套脚本放在:
from scipy import stats
n, heads = 20, 14
# 频率派:先区分单侧问题和双侧问题
one_sided = stats.binomtest(heads, n, p=0.5, alternative="greater").pvalue
two_sided = stats.binomtest(heads, n, p=0.5, alternative="two-sided").pvalue
# 贝叶斯:Beta(2,2) 先验后的后验概率
post_a, post_b = 2 + heads, 2 + n - heads
prob_gt_06 = 1 - stats.beta.cdf(0.6, post_a, post_b)
print(f"单侧 p 值: {one_sided:.3f}")
print(f"双侧 p 值: {two_sided:.3f}")
print(f"后验: Beta({post_a}, {post_b})")
print(f"P(p > 0.6 | 数据) = {prob_gt_06:.3f}")
同一批数据,不是一个“对”、一个“错”,而是问题不同、输出不同。
正是。统计方法先服务问题,再服务习惯。
小率的笔记本
频率派强调长期重复中的错误率控制,贝叶斯强调看完数据后的信念更新。频率派区间和贝叶斯信用区间语义不同,p 值和后验概率也不是同一种东西。实战中按问题选工具,不必站队。